Méthodes d'évaluation des programmes
Informations archivées
Les informations archivées sont fournies aux fins de référence, de recherche ou de tenue de documents. Elles ne sont pas assujetties aux normes Web du gouvernement du Canada et n’ont pas été modifiées ou mises à jour depuis leur archivage. Pour obtenir ces informations dans un autre format, veuillez communiquez avec nous.
Chapitre 2 - STRATÉGIES D'ÉVALUATION
Le présent chapitre commence par une étude des types de conclusions qu'il est possible de tirer d'une évaluation des résultats d'un programme. Il traite des divers obstacles qui sapent typiquement la validité des conclusions de l'évaluation puis passe à un cadre conceptuel pour l'élaboration des stratégies d'évaluation, avant de se terminer par une analyse de la nécessité d'avoir recours à des stratégies de mesure multiples pour produire des conclusions crédibles.
2.1 Inférence causale en évaluation
L'évaluation est censée déterminer les résultats obtenus ou «causés» par un programme. Dans cette section, nous essayons de préciser la signification des déclarations sur les causes des résultats d'un programme; la section suivante est une analyse des problèmes d'établissement d'inférences causales.
Commençons par étudier les genres de résultats qu'un programme peut «causer». Dans le plus simple des cas, le programme produit des changements positifs. Cette interprétation suppose toutefois qu'aucun changement positif n'aurait, été constaté en l'absence du programme, ce qui n'est pas nécessairement le cas, car la situation aurait pu s'améliorer ou se détériorer quand même. De même, un programme peut maintenir le statu quo en empêchant la situation de se détériorer, et cela peut être son seul effet positif, de sorte qu'il est essentiel de déterminer son effet incrémentiel.
Il s'ensuit que, pour bien comprendre les résultats causés par un programme, nous devons savoir ce qui serait arrivé sans l'exécution d'un programme. Cette notion est la clé des inférences causales. Autrement dit, si l'on conclut qu'un programme a produit ou causé un certain résultat, cela signifie que, s'il n'avait pas existé, le résultat ne se serait pas concrétisé. Pourtant, cette interprétation de la causalité s'applique plus logiquement à certains programmes qu'à d'autres. Elle vaut particulièrement pour les programmes pouvant être considérés comme des interventions gouvernementales pour modifier le comportement de particuliers ou d'entreprises par l'octroi de subventions, la prestation de services ou l'application de règlements. Dans ces cas-là , il est logique et habituellement possible d'arriver à une estimation de ce qui se serait produit si le programme n'avait pas existé.
Il existe toutefois d'autres programmes (dans les secteurs des services médicaux, du contrôle de la circulation aérienne et de la défense, par exemple) qu'il faut considérer logiquement comme partie intégrante du cadre à l'intérieur duquel notre société et notre économie fonctionnent. Ils tendent à exister dans des contextes où l'État assume le rôle d'intervenant principal. En outre, ils sont habituellement universels, ce qui signifie, dans le langage des économistes, que leurs résultats sont des «biens publics». Leur évaluation pose des difficultés parce qu'ils ne se prêtent pas à un modèle d'évaluation dans lequel on les ramène à des interventions précises. En outre, ce sont des programmes permanents, dont l'envergure est habituellement trop grande pour qu'on puisse leur appliquer des méthodes d'évaluation classiques. Certains programmes peuvent faire exception à la règle, mais il reste qu'il faudrait soulever des questions sur la portée de l'évaluation dans le cadre de l'étude préparatoire, à l'intention du client.
Un des derniers aspects de la causalité présente une importance critique dans les cas où les résultats de l'évaluation doivent influer sur la prise de décisions. On ne peut généraliser à partir des résultats de programmes que l'évaluation a déterminés à moins que le programme lui-même ne puisse être reproduit. Si le programme ne peut exister qu'à un moment, à un endroit ou dans des conditions données, il devient très difficile d'établir des inférences crédibles sur ce qui se produirait dans l'éventualité où un programme analogue serait mis en oeuvre ailleurs dans d'autres circonstances.
2.2 Inférences causales
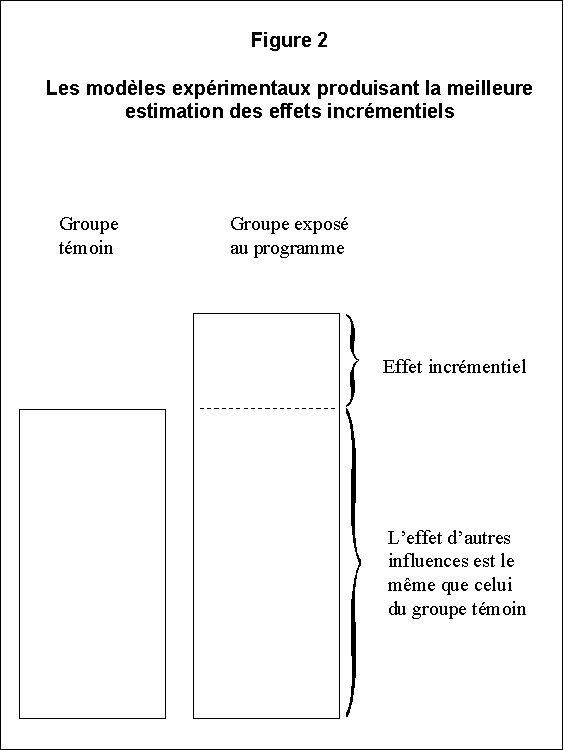
Conceptuellement, la façon d'établir une inférence causale semble évidente : il suffit de comparer deux situations absolument identiques, exception faite de leur exposition au programme. Toute différence entre deux situations peut être attribuée au programme. Ce principe fondamental est illustré à la figure 2. On choisit deux groupes identiques de sujets (des personnes, des entreprises et des écoles), un seul des deux (le groupe expérimental ou traité) étant exposé au programme, l'autre (le groupe témoin) étant soumis à toutes les mêmes influences extérieures que le groupe expérimental, hormis le programme. Les résultats postérieurs à l'exécution du programme sont mesurés de la même façon pour les deux groupes. À ce moment-là , on peut attribuer au programme n'importe quelle différence entre les résultats des deux groupes, puisque ceux-ci étaient au départ identiques et qu'ils ont été exposés aux mêmes influences extérieures.
Malheureusement, dans la pratique, il n'existe pas de modèle idéal susceptible d'être appliqué parfaitement, puisqu'on ne peut jamais pleinement obtenir l'équivalence absolue du groupe expérimental et du groupe témoin. Des groupes différents sont constitués de sujets différents et diffèrent donc à certains égards, même si les mesures moyennes d'une variable donnée sont identiques. En outre, à supposer que le même groupe serve à la fois de groupe expérimental et de groupe témoin, les observations antérieures et postérieures au programme sont faites à des moments différents, de sorte que d'autres facteurs peuvent influer sur les résultats observés après l'exécution du programme.
L'impossibilité d'atteindre à l'équivalence absolue sape la validité de l'inférence causale, de sorte qu'il est plus difficile pour les décideurs de déterminer le rendement antérieur du programme et de s'en inspirer dans leurs décisions à l'égard des programmes à venir. C'est d'autant plus complexe que les programmes gouvernementaux ne sont qu'un facteur parmi d'autres qui influent sur les résultats attendus. La rigueur de l'évaluation - et, par conséquent, son utilité pour le processus, décisionnel - est fonction de sa conformité au modèle idéal présenté auparavant.
Il s'ensuit que la capacité d'une inférence selon laquelle le programme a causé un certain résultat dépend, dans la pratique, de la mesure dans laquelle l'évaluation permet de rejeter comme d'autres explications plausibles, souvent appelées «obstacles à la validité de l'inférence causale». D'habitude, l'évaluation ne permet pas d'établir de façon concluante des rapports de cause à effet, mais elle permet de réduire l'incertitude à cet égard tout en produisant des éléments assez concluants pour qu'on puisse réfuter les autres hypothèses. Par exemple, l'évaluation pourrait produire des preuves que le programme est l'explication la plus probable du résultat observé, alors qu'à peu près rien d'autre ne prouve que les autres explications sont valables. Elle pourrait aussi permettre à l'évaluateur de distinguer et de quantifier les effets des autres facteurs en jeu ou des autres explications possibles. Bref, faire des inférences causales sur les résultats signifie qu'on rejette ou infirme les autres explications plausibles.
Revenons à notre exemple d'un programme d'aide à l'industrie en vue de créer des emplois. Si nous constatons la création d'un certain nombre d'emplois par les entreprises qui touchent une subvention, nous serions portés à conclure que c'est un effet attribuable au programme et que si celui-ci n'avait pas existé, les nouveaux emplois n'auraient pas été créés. Néanmoins, avant de pouvoir tirer cette conclusion, il nous faut examiner un certain nombre d'autres explications plausibles. Il se pourrait, par exemple, que les nouveaux emplois aient été créés par suite d'une reprise économique dans le secteur d'activité en question. De même, on pourrait aussi alléguer que les entreprises qui ont créé les emplois avaient l'intention de le faire de toute façon, et que les subventions étaient à toutes fins utiles des paiements de transfert inespérés. Afin de préciser l'effet incrémentiel d'un programme sur la création d'emplois, il faudrait avoir rejeté toutes ces autres explications, voire d'autres encore, ou bien tenir compte de leur influence.
L'élimination des autres explications (celles qui font obstacle à la validité de l'inférence causale posée comme hypothèse) ou l'estimation de leur importance relative est le principal objet d'une évaluation ayant pour but d'établir les résultats d'un programme. C'est une démarche fondée sur une combinaison d'hypothèses, d'éléments logiques et d'analyses empiriques; dans ce manuel, nous appelons chacune de ces approches une stratégie d'évaluation.
Revenons encore à l'exemple du programme d'aide à l'industrie : il serait possible de réfuter la conclusion que la création d'emplois résulte d'une reprise économique générale en prouvant qu'il n'y a pas eu de reprise dans la région où l'entreprise est établie (ou dans son secteur de l'économie). Pour ce faire, on étudierait des entreprises du même genre qui n'ont pas reçu de subvention. Si l'on devait constater que des emplois ont été créés uniquement dans celles qui ont touché une subvention, l'explication d'une reprise économique ne serait plus plausible. D'un autre côté, on pourrait remarquer qu'il s'est créé plus de nouveaux emplois dans les entreprises qui ont obtenu une subvention que dans les autres, auquel cas il serait toujours possible de rejeter l'explication d'une reprise en attribuant au programme la différence entre le nombre d'emplois créés dans les deux groupes d'entreprises (à condition, bien entendu, que les deux groupes se ressemblent suffisamment). Il convient de souligner que cette constatation modifie la conclusion initiale - à savoir que tous les nouveaux emplois sont attribuables au programme - compte tenu de l'effet d'une reprise économique. De plus, malgré ses limitations, ce modèle de comparaison permet d'éliminer bon nombre d'explications, y compris celle que les entreprises auraient créé les emplois en question de toute façon. Dans cet exemple, si ces deux autres explications sont les seules qu'on juge vraisemblables, la conclusion que le nombre accru de nouveaux emplois est attribuable au programme deviendrait assez plausible, d'après les éléments de preuve présentés. Toutefois, comme nous le verrons au chapitre suivant, il y a de plus fortes chances que les deux groupes d'entreprises n'aient pas été tout à fait semblables, de sorte que d'autres obstacles sapent la validité des conclusions. En pareil cas, il faut élaborer d'autres stratégies d'évaluation pour éliminer ces obstacles.
Jusqu'ici, nous avons tenté de déterminer dans quelle mesure un programme produit un résultat observé. Il reste un autre facteur qui vient compliquer l'équation : même si le programme est indispensable pour que le résultat se produise, il n'est pas nécessairement suffisant. Autrement dit, le résultat peut aussi être attribuable à d'autres facteurs, en l'absence desquels il n'est pas atteint. Sans le programme, il n'y a pas de résultat, mais cela ne signifie pas nécessairement que son existence assurera le résultat désiré. Tout ce qu'on peut déduire, c'est que le résultat se produira si le programme est mis en oeuvre et que les autres facteurs favorables sont réunis.
L'intérêt de ces autres facteurs s'explique du fait que, lorsqu'on a abouti à une conclusion au sujet de l'effet d'un programme existant, on veut normalement la généraliser en l'appliquant à d'autres lieux, à d'autres moments ou à d'autres situations. Cette possibilité de généraliser, appelée la validité externe de l'évaluation, se limite à affirmer que, dans des conditions identiques, la mise en oeuvre du programme ailleurs entraînerait le même résultat. Bien sûr, ni les conditions, ni le programme ne peuvent être parfaitement reproduits, de sorte que les inférences de ce genre sont souvent chancelantes au point que, pour les rendre crédibles, il faut poser de nouvelles hypothèses, trouver d'autres arguments logiques ou réaliser d'autres analyses empiriques. Il peut alors être utile d'avoir recours à des stratégies d'évaluation multiples.
Revenons une fois de plus à l'exemple du programme de subventions à l'industrie. Qu'arrivera-t-il si nous devons établir que le programme existant a effectivement permis de créer un certain nombre d'emplois, grâce à certaines compétences en marketing et à d'autres facteurs? Ce résultat peut être utile du point de vue de la responsabilisation, mais les questions posées au sujet de l'élaboration de nouveaux programmes devraient alors normalement porter sur l'opportunité de poursuivre le programme, de lui donner de l'expansion ou d'en réduire l'ampleur. La validité externe de la conclusion selon laquelle la poursuite ou l'expansion du programme entraînerait la création de nouveaux emplois pourrait être sujette à caution si l'échantillon des entreprises étudiées n'était pas représentatif de toutes celles auxquelles le programme s'appliquerait, ou si les conditions qui ont contribué au succès du programme dans le passé étaient peu susceptibles de se reproduire. Il se pourrait que les autres entreprises n'aient pas les aptitudes en marketing nécessaires, de sorte que le programme élargi n'aurait pas un effet comparable sur elles. Bref, c'est compte tenu de la question à l'étude et du genre de décisions à prendre que l'évaluateur pourra cerner d'autres facteurs explicatifs et explorer leurs liens avec le programme.
Il existe diverses stratégies pour qui veut minimiser l'effet des obstacles à la validité externe, tout comme à la validité interne, d'ailleurs. Malheureusement, elles ne sont pas toujours compatibles, de sorte qu'il faut parfois opter pour une solution de compromis. Quand l'évaluateur doit formuler des conclusions crédibles sur lesquelles la direction peut se fonder utilement, il est clair que, malgré l'importance indéniable de la validité interne, la validité externe de l'évaluation ne saurait être négligée. L'évaluateur devrait toujours être conscient du genre de décisions à prendre et, partant, du genre de conclusions qu'il doit présenter. Il doit donc bien comprendre les principaux obstacles à la validité externe, si des points ne sont pas traités, ainsi qu'à la crédibilité et à l'utilité de ces conclusions pour les décideurs.
Résumé
Les difficultés d'établissement d'inférences causales quant aux programmes et à leurs résultats sont l'un des principaux thèmes du manuel. L'autre thème principal est celui de la mesure des résultats. Avant de pouvoir tirer des conclusions sur les effets d'un programme, l'évaluateur doit être conscient des autres facteurs ou des autres circonstances susceptibles d'expliquer les résultats observés, puis présenter des arguments pour réfuter ces explications. S'il fait des généralisations à partir de ses conclusions, il devrait surveiller de près les obstacles à la validité externe de son évaluation. Les méthodes utilisées pour déterminer les résultats d'un programme sont bonnes dans la mesure où elles permettent de produire les meilleurs arguments possibles, compte tenu des ressources et du temps disponibles.
Références : Inférence causale
Campbell, D.T. et J.C. Stanley, Experimental and Quasi-experimental Designs for Research, Chicago : Rand-McNally, 1963.
Cook, T.D. et D.T. Campbell,Quasi-experimentation : Design and Analysis Issues for Field Settings, Chicago : Rand-McNally, 1979.
Cook, T.D. et C.S. Reichardt, éd.,Qualitative and Quantitative Methods in Evaluation Research, Thousand Oaks : Sage Publications, 1979.
Heise, D.R., Causal Analysis, New York : Wiley, 1985.
Kenny, D.A., Correlation and Causality, Toronto : John Wiley and Sons, 1979.
Suchman, E.A., Evaluative Research : Principles and Practice in Public Service and Social Action Programs, New York : Russell Sage, 1967.
Williams, D.D., éd., Naturalistic Evaluation, Vol. 30 de New Directions in Program Evaluation, San Francisco : Jossey-Bass, 1986.
2.3 Stratégies d'évaluation
Il faut tenir compte de deux types de facteurs afin d'élaborer des méthodes de détermination des résultats d'un programme : les facteurs qui sont liés à la recherche (autrement dit à la qualité des éléments de preuve réunis) et les facteurs qui découlent du contexte décisionnel dans lequel l'évaluation a lieu. Les deux facteurs sont importants, mais, quoi qu'il en soit, il faut ordinairement concilier la rigueur scientifique de l'évaluation et sa pertinence pour les décideurs.
Il existe plusieurs façons de recueillir les données sur lesquelles on se fonde pour déterminer les résultats d'un programme. Dans ce chapitre, nous étudions les principales stratégies d'évaluation, qui comprendront toutes un modèle d'évaluation (chapitre 3), une méthode de collecte des données (chapitre 4) et une méthode analytique (chapitre 5).
Dans notre exemple du programme d'aide à l'industrie, on pourrait décider de déterminer si les emplois créés sont attribuables au programme en menant une enquête auprès des entreprises participantes pour leur demander ce qui serait arrivé s'il n'y avait pas eu de subvention gouvernementale. Une autre stratégie pourrait consister à faire un sondage pour déterminer le nombre d'emplois créés dans des entreprises analogues, les unes ayant reçu une subvention et les autres pas, puis à comparer les résultats afin de mesurer les importantes différences statistiques. Une troisième stratégie pourrait faire appel à des études de cas approfondies sur des entreprises ayant bénéficié d'une subvention pour déterminer si elles auraient vraisemblablement créé les emplois en question de toute façon. Chacune de ces stratégies porte sur la même question et fournit des preuves de nature et de qualité différentes; aucune ne fournit normalement de preuve incontestable des résultats du programme. C'est pourquoi il est donc souvent approprié d'avoir recours à plusieurs stratégies. Par exemple, on peut vouloir aussi déterminer les effets du programme à d'autres égards, celui de la concurrence déloyale que les subventions auraient pu créer. Cela pourrait se faire en partie au moyen d'une des stratégies susmentionnées, et en partie aussi grâce à une stratégie différente. La stratégie globale pour laquelle l'évaluateur opte est le plus souvent une combinaison de stratégies différentes conçue pour trancher une série de questions précises. À la section 2.4.3, nous verrons comment on élabore de telles stratégies ou des démarches d'évaluation multiples.
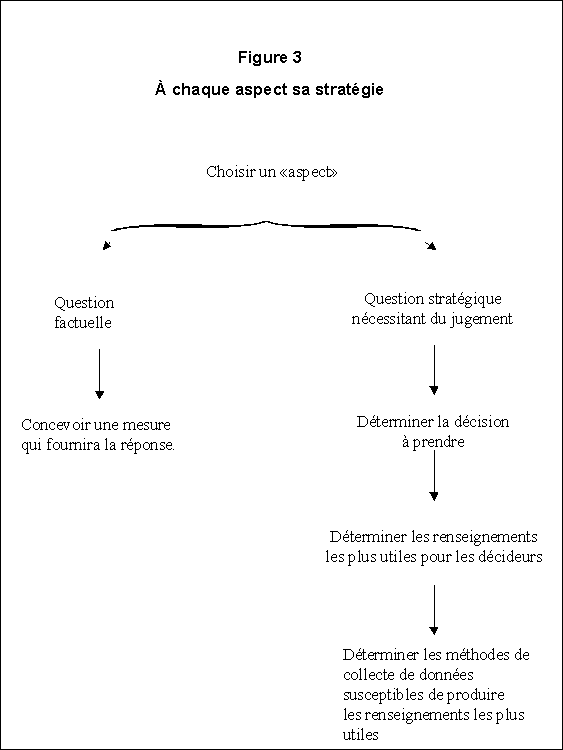
La figure 3 illustre les étapes générales de l'élaboration d'une stratégie d'évaluation. Il est utile d'envisager cette démarche comme une série d'étapes que nous décrivons dans l'ordre, bien qu'elle soit beaucoup plus itérative dans la pratique, puisque chaque étape est étroitement liée aux autres.
Pour commencer, l'évaluateur doit choisir un modèle. Le modèle d'évaluation s'entend du modèle logique utilisé pour parvenir à des conclusions sur les résultats. Afin de le choisir, l'évaluateur doit déterminer simultanément le genre d'information qu'il veut obtenir et le type d'analyse auquel il va soumettre cette information. Par exemple, si l'évaluation a pour objet de déterminer dans quelle mesure un programme a atteint un objectif donné, l'évaluateur doit choisir un indicateur approprié et opter pour une méthode d'analyse qui lui permettra d'isoler l'effet du programme. Les modèles d'évaluation servent de base logique pour mesurer des résultats et les attribuer aux programmes.
Une fois le modèle d'évaluation choisi, l'évaluateur passe au choix des méthodes et des techniques nécessaires pour l'appliquer. Le genre d'information nécessaire - indicateurs qualitatifs ou indicateurs quantitatifs de la réalisation des objectifs- est déterminé à l'étape de la conception du modèle. L'étape suivante consiste à définir les données nécessaires pour produire cette information. Les données sont des faits, c'est-à -dire des choses qu'on peut observer et consigner et leur nature et leur qualité peuvent varier nettement. À cet égard, la tâche de l'évaluateur se complique parce que les données sont plus ou moins accessibles et que leur coût et leur pertinence varient. C'est là qu'intervient la question de la mesure, puisqu'il faut décider quelles données sont les plus pertinentes et comment les recueillir. Comme nous le verrons ultérieurement, la mesure est une question méthodologique d'importance cruciale pour l'évaluation.
Après avoir bien défini les données nécessaires, l'évaluateur doit déterminer leurs sources potentielles. S'il lui est impossible d'obtenir des données fiables d'une source secondaire, il doit avoir recours à une méthode de collecte de données primaires (Cook et Campbell, 1970, chapitre 1; Cronbach, 1982, chapitre 4). Cette approche est généralement plus coûteuse que celle de l'utilisation de données secondaires, et on devrait s'en écarter dans la mesure du possible. Lorsqu'on décide de recueillir des données primaires, il faut normalement choisir une méthode de collecte (observations sur le terrain et sondages postaux, par exemple), mettre au point des instruments de mesure (questionnaires, guides d'entrevue, fiches d'enregistrement des observations, etc.) et formuler un plan d'échantillonnage.
Enfin, compte tenu du type d'analyse nécessaire et du genre de données disponibles, l'évaluateur doit choisir des méthodes d'analyse des données (analyse coûts-avantages, régression multiple, analyse de la variance, etc.). Ces analyses ont pour objet de traduire les données recueillies pour produire l'information nécessaire pour l'évaluation.
2.4 Évaluations crédibles
Avant d'analyser les éléments précis d'une stratégie d'évaluation de façon plus détaillée, nous devrions examiner les éléments clés dont on doit tenir compte pour assurer la crédibilité de l'évaluation elle-même. Ces éléments clés sont résumés au tableau 2.
|
Tableau 2 - Éléments nécessaires à la crédibilité des évaluations |
A. Critères de recherche
|
B. Critères du contexte décisionnel
|
2.4.1 Critères de recherche
a) Questions de mesure
Bien des effets des programmes sont fondamentalement difficiles à mesurer. Voici quelques exemples :
- amélioration du bien-être des personnes âgées, grâce à des programmes leur permettant de continuer à vivre seules chez elles;
- amélioration de la sécurité nationale grâce à la mise au point d'un important système d'armes;
- amélioration des stimulants à la R-D industrielle grâce à des modifications du régime fiscal.
Comme bien d'autres, ces effets exigent à la fois des méthodes de mesure perfectionnées et une connaissance approfondie de domaines spécialisés de la politique publique.
Trois des aspects de la mesure nécessitent une attention particulière : la fiabilité, la validité de la mesure, ainsi que la profondeur et la portée.
Fiabilité
Une mesure est dite fiable si elle donne les mêmes résultats lorsqu'elle est appliquée de façon répétée dans une situation donnée. Par exemple, un test d'intelligence serait considéré comme fiable dans la mesure où il donnerait un résultat identique s'il était administré deux fois à la même personne (dont l'intelligence n'aurait pas changé). Dans le contexte d'un programme, la fiabilité peut correspondre à la stabilité de la mesure dans le temps, ou à son uniformité d'un endroit à l'autre.
Le manque de fiabilité peut être attribuable à plusieurs facteurs. Par exemple, il peut résulter d'une mauvaise méthode de collecte des données : si l'enquêteur ne lit pas attentivement les instructions du guide d'entrevue, il risque d'obtenir des résultats légèrement différents de ceux des enquêteurs qui les ont lues. Le manque de fiabilité peut aussi être imputable à l'instrument de mesure lui-même, ou au plan d'échantillonnage. Si la procédure d'échantillonnage n'est pas bien suivie, l'échantillon risque de ne pas être représentatif de la population visée et, par conséquent, les résultats qu'il génère peuvent n'être pas fiables.
Validité de la mesure
Une mesure est valide dans la mesure où elle représente fidèlement ce qu'elle est censée représenter. Les mesures (indicateurs) valides ne présentent pas d'erreurs systématiques et saisissent les données voulues. Les données signifient-elles ce que nous croyons qu'elles signifient? La technique employée mesure-t-elle ce qu'elle est censée mesurer? Ces questions ont une importance critique pour l'évaluation des programmes.
Les problèmes de validité d'une mesure peuvent être conceptuels ou techniques. À moins d'y avoir bien réfléchi, il est rare qu'on sache exactement quelles données correspondent le mieux aux résultats à mesurer. La décision est trop souvent fondée uniquement sur des données faciles à obtenir, mais qui génèrent des mesures moins probantes qu'on n'aurait pu le souhaiter. En outre, des erreurs techniques (de mesure et d'échantillonnage, par exemple) peuvent se produire et fausser les résultats de l'évaluation.
Profondeur et portée
Les notions de profondeur et de portée sont indissociables de celles de la fiabilité et de la validité de la mesure. Dans certaines situations, l'évaluateur peut souhaiter mesurer certains résultats très précisément et d'autres de façon moins détaillée, mais avec plusieurs instruments différents.
Pour mesurer les avantages d'un programme pour une personne, il faut parfois réaliser des entrevues et des sondages en profondeur. Dans certains cas, il peut arriver aussi qu'on doive avoir recours à différents indicateurs reflétant tous des points de vue distincts sur les conséquences envisagées. Par exemple, lorsqu'on évalue l'effet d'une subvention pour une entreprise, il peut être nécessaire d'analyser ses ventes, l'évolution de son effectif, celle de la qualité de ses emplois, l'effet de l'achat de nouvelles machines sur sa compétitivité, et ainsi de suite.
Par ailleurs, la population cible d'un programme peut être importante et hétérogène, auquel cas il est important que l'évaluation porte de façon relativement peu détaillée sur tous ses segments. Ainsi, pour évaluer convenablement les conséquences pour les entreprises d'un programme d'aide à un secteur d'activité donné, il faudrait prendre soin d'assurer une représentation suffisante de tous les types d'entreprises visées (grandes et petites, de différents secteurs et de régions différentes).
La profondeur et la portée de la mesure posent un problème épineux. Comme le temps et les ressources sont limités, l'évaluateur doit inévitablement négliger l'une au profit de l'autre. S'il privilégie la portée, son évaluation peut gagner en pertinence et avoir un champ d'application plus vaste, mais elle perd alors en profondeur, et les mesures individuelles sont alors moins valides et moins fiables.
b) Questions d'attribution
Le programme n'est souvent qu'un des nombreux facteurs influant sur le résultat constaté. En fait, il peut être assez difficile de déterminer dans quelle proportion les résultats sont vraiment attribuables au programme plutôt qu'à d'autres facteurs. C'est peut-être l'aspect le plus difficile d'une étude d'évaluation.
La clé de l'attribution des résultats est donc une bonne comparaison. En laboratoire, il est possible de le faire grâce à des groupes témoins rigoureusement contrôlés. Par contre, dans le cas des programmes du gouvernement fédéral, les comparaisons qui sont généralement possibles sont moins rigoureuses, et de nombreux obstacles risquent de saper la validité interne et la validité externe.
Les obstacles à la validité interne les plus courants sont les suivants :
- événements historiques - événements externes influant sur les participants au programme autrement que sur les membres des groupes témoins;
- maturation - changements des résultats découlant du temps écoulé plutôt qu'attribuables au programme lui-même (p. ex., le vieillissement des participants d'un groupe comparativement à ceux d'un autre à une étape différente);
- attrition - abandon du programme par des répondants (ce facteur pourrait nuire à la comparabilité des groupes expérimental et témoin);
- biais de la sélection - propension initialement inégale des groupes expérimental et témoin à réagir au programme;
- facteurs de régression -pseudo-changements des résultats découlant de la rétention de personnes pour un programme en raison des résultats extrêmes obtenus (à la longue, tout groupe extrême a tendance à se rapprocher de la moyenne, qu'il ait bénéficié du programme ou pas);
- diffusion ou imitation du traitement - obtention par les répondants d'un groupe de l'information destinée à un autre groupe;
- essai - différences observées entre les groupes expérimental et témoin pouvant être imputables à une meilleure connaissance d'un instrument de mesure pour les membres du premier groupe;
- instruments - conséquence du changement de l'instrument utilisé selon le groupe (p. ex., lorsqu'on a recours à différents enquêteurs).
Il existe aussi de nombreux obstacles à la validité externe, autrement dit empêchant l'évaluateur de généraliser ses constatations pour les appliquer dans d'autres contextes, à d'autres moments ou à d'autres programmes. Dans le contexte de l'administration fédérale, la validité externe a toujours une grande importance, puisque les constatations de l'évaluation sont censées appuyer la prise de décisions ultérieures.
Il existe trois types d'obstacles à la généralisation des constatations :
- interaction entre la sélection et le programme - non-représentativité des effets sur les participants au programme, parce que ceux-ci ont une caractéristique (influant sur les effets) non représentative de l'ensemble de la population;
- interaction entre le contexte et le programme - non-représentativité du contexte du programme expérimental ou pilote comparativement à celui dans lequel le programme aurait été exécuté, s'il avait été entièrement mis en oeuvre;
- interaction entre les événements historiques et le programme - non-représentativité des conditions dans lesquelles le programme s'est déroulé par rapport aux conditions futures.
Lorsqu'on est appelé à choisir des stratégies d'évaluation, il est manifestement très utile d'être conscient des obstacles à leur validité. Une grande partie du jugement qui est nécessaire à la conception d'une évaluation ainsi qu'à la collecte et à l'analyse des données consiste à savoir trouver les moyens de déterminer les effets attribuables au programme. Pour y arriver, il faut établir de bonnes comparaisons, en évitant de donner prise au plus grand nombre d'obstacles possible à la validité.
Lorsque l'évaluation est axée sur les résultats, les modèles diffèrent surtout quant à l'efficacité avec laquelle ils permettent de déterminer les effets attribuables au programme et, le cas échéant, à la facilité de généralisation des conclusions. Les modèles d'évaluation sont présentés au chapitre 3, en ordre décroissant de crédibilité.
Références : Stratégies d'évaluation
Campbell, D.T. et J.C. Stanley, Experimental and Quasi-experimental Designs for Research, Chicago : Rand-McNally, 1963.
Cook, T.D. et D.T. Campbell, Quasi-experimentation : Designs and Analysis Issues for Field Settings, Chicago : Rand-McNally, 1979.
Kerlinger, F.N., Behavioural Research : A Conceptual Approach, New York : Holt, Rinehart and Winston, 1979, chapitre 9.
Mercer, Shawna L. et Vivek Goel, «Program Evaluation in the Absence of Goals : A Comprehensive Approach to the Evaluation of a Population-Based Breast Cancer Screening Program», Canadian Journal of Program Evaluation, Vol. 9, No 1, avril-mai 1994, p. 97 à 112.
Patton, M.Q., Utilization-focussed Evaluation (2e édition), Thousand Oaks : Sage Publications, 1986.
Rossi, P.H. et H.E. Freeman, Evaluation : A Systematic Approach (2e édition), Thousand Oaks : Sage Publications, 1989.
Ryan, Brenda et Elizabeth Townsend, «Criteria Mapping», Canadian Journal of Program Evaluation, Vol. 4, No 2, octobre-novembre 1989, p. 47 à 58.
Watson, Kenneth, «Selecting and Ranking Issues in Program Evaluations and Value-for-money Audits», Canadian Journal of Program Evaluation, Vol. 5, No 2, octobre-novembre 1990, p. 15 à 28.
2.4.2 Critères du contexte décisionnel
Puisque l'évaluation est censée faciliter la prise de décisions, les critères de choix d'une méthode d'évaluation appropriée doivent garantir l'obtention d'une information utile. Cela suppose qu'on comprenne le contexte dans lequel les décisions seront prises et où les constatations de l'évaluation seront présentées. Il faut donc tenir compte de facteurs qui s'ajoutent aux aspects techniques des méthodes, bien que celles-ci conservent une importance critique pour la crédibilité des constatations.
L'élaboration d'une démarche d'évaluation des résultats d'un programme peut donc devenir une tâche très délicate, qui tient probablement plus de l'art que de la science, puisqu'il faut tenir compte à la fois des avantages et des inconvénients des stratégies envisagées pour recueillir des données et du contexte dans lequel l'évaluation se déroule. La conciliation de ces deux éléments doit en outre se faire en fonction des contraintes imposées par les ressources et le temps limité dont l'évaluateur dispose. Bref, c'est une tâche qui exige de toute évidence l'expérience de la recherche, et de la gestion.
Lorsqu'on examine les démarches d'évaluation possibles à l'étape préparatoire de la planification, il faudrait constamment se poser la question suivante : la méthode ou solution recommandée fournira-t-elle des données suffisantes sur les questions visées, dans les délais fixés et sans dépasser le budget? Le tableau 2 présente deux éléments dont il faut se rappeler dans le contexte décisionnel : le degré auquel on peut s'attendre que la méthode aboutisse à des conditions crédibles et celui auquel elle peut être appliquée. Nous allons maintenant décrire chacun de ces éléments généraux en traitant aussi des questions connexes qui sont décrites ci-dessous. Il convient de souligner que ces éléments s'appliquent à tous les aspects de l'évaluation, pas seulement à ceux qui sont liés aux résultats du programme.
a) Formulation de conclusions crédibles (recommandations judicieuses fondées sur une analyse précise)
-
La démarche d'évaluation devrait tenir compte de la possibilité de formuler des conclusions crédibles.
On recueille des données afin de formuler des conclusions objectives et crédibles basées sur elles, avec assez de preuves à l'appui pour qu'on y ajoute foi. Il peut être difficile d'aboutir à de telles conclusions, et l'évaluateur devrait en tenir compte lorsqu'il élabore sa stratégie. En outre, la crédibilité des conclusions est en partie fonction de leur formulation, autrement dit de leur présentation.
-
Les données recueillies et les conclusions formulées devraient être objectives, et toutes les hypothèses devraient être clairement précisées.
L'objectivité des évaluations est extrêmement importante. En effet, elles sont souvent contestées par quelqu'un, soit un gestionnaire de programme, un client, un membre de la haute direction, un représentant d'un organisme central ou un ministre. L'objectivité signifie que les données et les conclusions peuvent être vérifiées et confirmées par d'autres personnes que les auteurs de l'évaluation. Autrement dit, les conclusions doivent découler de l'information recueillie. L'information et les données d'évaluation devraient donc être réunies, analysées et présentées de telle façon que d'autres personnes qui feraient la même évaluation en se fondant sur les mêmes hypothèses de base aboutiraient à des conclusions analogues. C'est beaucoup plus difficile à faire lorsqu'on opte pour certaines stratégies d'évaluation que pour d'autres, notamment si la stratégie utilisée repose largement sur le jugement professionnel de l'évaluateur. En particulier, on devrait toujours préciser clairement au lecteur les éléments sur lesquels les conclusions sont fondées (l'information et les données recueillies ainsi que les hypothèses posées). Si les conclusions sont ambiguës, il est particulièrement important que les hypothèses sous-jacentes soient clairement énoncées. En effet, lorsqu'elles ne sont pas bien précisées, il arrive souvent que les conclusions soient mal formulées.
-
Les conclusions doivent être pertinentes, c'est-à -dire compatibles avec le contexte décisionnel et elles doivent absolument porter sur les questions étudiées.
Au cours d'une étude, les chercheurs perdent parfois de vue les questions sur lesquelles l'examen doit porter; il devient alors difficile pour le lecteur (le client de l'évaluation) de comprendre le lien entre les conclusions et les questions à évaluer cernées au départ. Ce phénomène peut être dû à plusieurs facteurs. Il se peut par exemple que la stratégie d'évaluation n'ait pas été suffisamment bien conçue, de sorte qu'il est difficile d'obtenir de l'information valide sur certaines questions et de tirer certaines conclusions. Par ailleurs, il est possible aussi que les intérêts de l'évaluateur l'emportent, auquel cas les questions qui intéressent la haute direction ne reçoivent pas toute l'attention voulue. Enfin, d'autres questions peuvent se poser pendant qu'on étudie le programme et son contexte. Cela ne devrait toutefois pas présenter de difficulté, pourvu que les questions initiales soient bel et bien étudiées et qu'on précise clairement les questions supplémentaires et les conclusions correspondantes.
-
La précision des conclusions est largement fonction de la qualité et de la nature de l'information recueillie, lesquelles devraient être choisies compte tenu des facteurs contextuels.
On constate souvent deux types de difficultés dans les évaluations. Il est souvent impossible d'arriver à des conclusions définitives, et l'information et les données recueillies grâce aux stratégies utilisables ne sont pas complètes.
Dans le premier cas, il est fréquent qu'on n'arrive pas à prouver catégoriquement le rapport de causalité entre un programme et un résultat observé, en raison surtout de l'impossibilité de surmonter les problèmes de mesure et d'attribution dont nous avons déjà fait état. En général, il est peu probable qu'une stratégie d'évaluation produise à elle seule suffisamment d'informations pour donner une réponse sans équivoque aux questions posées.
Cela nous amène directement au second type de difficultés : il y a normalement plusieurs stratégies d'évaluation envisageables, chacune produisant de l'information et des données de qualité et de nature différentes. Il s'ensuit donc qu'il faudrait choisir la stratégie en se fondant sur les facteurs contextuels liés aux décisions à prendre au sujet du programme, et pas seulement sur des questions de recherche prédéfinies. C'est sensiblement la même chose qu'en droit, où le genre d'éléments de preuve à produire est fonction de la gravité et du type de crime. Ainsi, dans bien des poursuites au civil, il suffit de prouver l'existence de motifs raisonnables, alors que la culpabilité d'un criminel doit être prouvée «au-delà de tout doute raisonnable» (Smith, 1981). Les facteurs contextuels dont l'évaluateur devrait tenir compte sont le degré d'incertitude sur le programme et sur ses résultats, l'importance de ses effets, son coût et la probabilité que les conclusions soient contestées. Il devrait être capable de prévoir quelles contestations d'envergure ses conclusions susciteront éventuellement, et être prêt à les réfuter.
Le choix de l'information à recueillir et, partant, de la méthode d'évaluation à utiliser est l'une des tâches les plus difficiles pour l'évaluateur. En principe, c'est le client de l'étude et non l'évaluateur qui fera ce choix. La tâche de l'évaluateur consiste à présenter au client les démarches d'évaluation susceptibles de générer les conclusions crédibles qu'on attend de lui, à un coût et dans des délais raisonnables. Pour choisir la démarche, le client devrait avoir une bonne compréhension de l'information qui sera produite et être par conséquent en mesure de juger si l'évaluation est suffisamment rigoureuse pour pouvoir s'en inspirer dans ses décisions. Bien entendu, l'évaluateur devrait proposer des démarches d'évaluation qui reflètent le mieux possible le contexte décisionnel afin de faciliter le choix du client.
-
Les conclusions formulées devraient être fondées sur un examen exhaustif des questions pertinentes.
L'exhaustivité - ou son absence - est un autre facteur qui pose souvent des problèmes aux évaluateurs. (Bien qu'elle soit liée à la pertinence de l'information, elle constitue un point distinct dans le tableau 2, parce qu'on a souvent tendance à produire de l'information et des données objectives et pertinentes sur la plupart des questions à l'étude, mais à en négliger plus ou moins d'autres.) Il s'agit là d'un problème de macromesure. L'évaluateur devrait s'efforcer d'avoir une idée aussi exacte que possible de la question du point de vue du client. Cela suppose qu'il étudie toutes les questions d'intérêt qu'il peut, compte tenu du temps et des ressources financières dont il dispose. À cet égard, il ne faut jamais oublier que, pour le gouvernement fédéral, le «client» est en définitive le public canadien. Il est parfois difficile de faire en sorte que la portée de l'évaluation soit suffisante. Pourtant, si l'on décide de la sacrifier pour analyser de façon plus approfondie certaines des questions envisagées, on risque d'aboutir à des conclusions correctes, mais sans vue d'ensemble. Pour éviter cet écueil, on prend habituellement soin de discuter des questions d'évaluation avec le client et avec d'autres parties ayant des points de vue différents. De cette façon, on a toutes les chances d'arriver à une stratégie d'évaluation d'une portée satisfaisante.
Si l'évaluateur estime que sa tâche consiste à fournir un complément d'information pertinente sur un programme et sur ses résultats (autrement dit de proposer une méthode permettant de réduire l'incertitude au sujet d'un programme) plutôt qu'à produire des preuves concluantes de son efficacité, il aboutira donc vraisemblablement à des conclusions plus utiles. Avec cette approche, il risque de devoir faire des choix difficiles entre la pertinence et la rigueur de son travail, mais il doit choisir des méthodes d'évaluation qui lui permettront de maximiser les chances d'arriver à des conclusions utiles, même avec des réserves.
-
Enfin, on devrait clairement distinguer les constatations des recommandations de l'évaluation.
L'évaluateur peut être fréquemment appelé à donner des conseils à son client et à lui présenter des recommandations. Il doit alors absolument établir une distinction entre les constatations qui sont tirées de l'information générée par son étude et les recommandations sur le programme qui s'inspirent des conclusions de son évaluation ou de renseignements provenant d'autres sources, par exemple des directives stratégiques. Les conclusions de l'évaluation perdent de leur crédibilité si cette distinction n'est pas maintenue.
Par exemple, les constatations d'une évaluation d'un programme d'économie d'énergie résidentielle peuvent permettre à l'évaluateur de conclure que le programme a eu des répercussions favorables sur l'économie d'énergie. Toutefois, des renseignements obtenus d'autres sources peuvent laisser entendre que d'autres programmes d'économie d'énergie sont plus rentables, auquel cas l'évaluateur est porté à recommander que le programme résidentiel soit abandonné. Dans ce cas-là , il doit clairement préciser que sa recommandation n'est pas fondée sur l'information obtenue dans le contexte de l'évaluation elle-même, mais bien sur d'autres renseignements.
b) Questions pratiques
-
Lorsqu'il élabore sa méthode d'évaluation, l'évaluateur doit tenir compte d'éléments fondamentaux tels que la praticabilité, la viabilité financière et l'éthique.
Une démarche est jugée praticable dans la mesure où elle peut être appliquée efficacement sans conséquences néfastes et dans les délais impartis. La viabilité financière s'entend du coût de mise en oeuvre de la démarche. Il se peut que le coût d'utilisation de la méthode considérée comme la plus appropriée dans une situation donnée soit exorbitant. Or, il faut toujours préférer la méthode d'évaluation susceptible à la fois de gérer les problèmes de mesure et d'attribution et d'aboutir à des conclusions crédibles, tout en pouvant être appliquée dans les limites des ressources disponibles.
L'éthique (principes ou valeurs morales) doit être évaluée dans l'élaboration d'une méthode d'évaluation. Par exemple, il peut être contraire à l'éthique d'exécuter un programme exclusivement pour un sous-groupe d'une population donnée. Ce serait le cas si une évaluation portant sur un programme social devait être fondée sur un échantillon aléatoire de prestataires et privait de services d'autres personnes y ayant pourtant autant droit. Les principes d'éthique dont il faut tenir compte dans le contexte des évaluations de programmes de l'administration fédérale sont précisés dans divers textes législatifs et stratégiques sur la collecte, l'utilisation, la préservation et la diffusion de l'information, dont la Loi sur l'accès à l'information, la Loi sur la protection des renseignements personnels et la Loi sur la statistique, ainsi que la Politique du gouvernement en matière de communications et la Politique sur la gestion des renseignements détenus par le gouvernement du Conseil du Trésor, laquelle porte notamment sur les mesures à prendre pour minimiser la collecte de données inutile et pour assurer l'examen méthodologique préalable des activités de collecte de données.
Références - Le contexte décisionnel
Alkin, M.C., A Guide for Evaluation Decision Makers, Thousand Oaks : Sage Publications, 1986.
Baird, B.F., Managerial Decisions under Uncertainty, New York : Wiley Interscience, 1989.
Cabatoff, Kenneth A., «Getting On and Off the Policy Agenda : A Dualistic Theory of Program Evaluation Utilization», Canadian Journal of Program Evaluation,. Vol. 11, No 2, automne 1996, p. 35 à 60.
Ciarlo, J., éd., Utilizing Evaluation, Thousand Oaks : Sage Publications, 1984.
Goldman, Francis et Edith Brashares, «Performance and Accountability : Budget Reform in New Zealand», Public Budgeting and Finance, Vol. 11, No 4, hiver 1991, p. 75 à 85.
Mayne, John et R.S. Mayne, «Will Program Evaluation be Used in Formulating Policy?», in Atkinson, M. et M. Chandler, éd., The Politics of Canadian Public Policy, Toronto : University of Toronto Press, 1983.
Moore, M.H., Creating Public Value : Strategic Management in Government, Boston : Harvard University Press, 1995.
Nutt, P.C. et R.W. Backoff, Strategic Management of Public and Third Sector Organizations, San Francisco : Jossey-Bass, 1992.
O'Brecht, Michael, «Stakeholder Pressures and Organizational Structure», Canadian Journal of Program Evaluation, Vol. 7, No 2, octobre-novembre 1992, p. 139 à 147.
Peters, Guy B. et Donald J. Savoie, Centre canadien de gestion, Governance in a Changing Environment, Montréal et Kingston : McGill-Queen's University Press, 1993.
Pressman, J.L. et A. Wildavsky, Implementation, Los Angeles : UCLA Press, 1973.
Reavy, Pat, et al., «Evaluation as Management Support : The Role of the Evaluator», Canadian Journal of Program Evaluation, Vol. 8, No 2, octobre-novembre 1993, p. 95 à 104.
Rist, Ray C., éd., Program Evaluation and the Management of the Government, New Brunswick (NJ) : Transaction Publishers, 1990.
Schick, Allen, The Spirit of Reform : Managing the New Zealand State, rapport commandé par le ministère du Trésor et la Commission des services gouvernementaux de la Nouvelle-Zélande, 1996.
Seidle, Leslie, Rethinking the Delivery of Public Services to Citizens, Montréal : Institut de recherches en politiques publiques (IMPP), 1995.
Thomas, Paul G., The Politics and Management of Performance Measurement and Service Standards, Winnipeg : St.-John's College, University of Manitoba, 1996.
2.4.3 Stratégies multiples
Une stratégie d'évaluation produit des preuves d'un résultat, tandis qu'une étude d'évaluation porte ordinairement sur plusieurs questions, ce qui signifie qu'on a donc intérêt à faire appel à plusieurs stratégies, d'autant plus qu'il peut aussi être souhaitable d'en utiliser plus d'une pour examiner une question donnée, afin d'accroître l'exactitude et la crédibilité des constatations de l'évaluation.
La plupart des stratégies d'évaluation élaborées pour étudier une question précise peuvent aussi être utilisées pour en examiner d'autres, avec certaines modifications. Même si une stratégie n'est pas idéale pour étudier une autre question, il peut être utile de s'en servir parce que son coût marginal est faible. Supposons par exemple qu'on fasse une étude afin de déterminer l'aptitude à la lecture de deux groupes, dont l'un participant à un programme donné. On fait passer aux membres de chaque groupe un test destiné à mesurer leur aptitude à la lecture, en leur posant aussi diverses questions sur l'utilité et l'efficacité du programme. Les résultats reflètent bien entendu les lacunes inhérentes à tous les résultats des enquêtes sur les attitudes, mais ajoutent quand même des indications aux résultats objectifs du test de lecture, à un coût relativement faible.
La seconde raison d'envisager le recours à plusieurs stratégies de recherche dans une évaluation, c'est qu'il est souvent souhaitable de mesurer ou d'évaluer le même résultat en fonction de plusieurs sources de données, ou en appliquant des modèles d'évaluation différents. En effet, il est souvent difficile, sinon impossible, de mesurer exactement et sans équivoque un résultat donné. Des facteurs de confusion, des erreurs de mesure et des préjugés personnels risquent de se combiner pour saper la validité ou la fiabilité des résultats obtenus lorsqu'on n'a utilisé qu'une seule et unique méthode d'analyse. En effet, les modèles d'évaluation sont habituellement vulnérables à plusieurs obstacles à la validité interne; il est donc impossible d'éliminer ou de tenir compte de toutes les autres explications plausibles. Par conséquent, on doit souvent avoir recours à des stratégies complémentaires pour infirmer les explications indésirables des résultats observés.
C'est pour ces deux raisons qu'il est préférable d'étudier les questions à évaluer de plusieurs points de vue, en se fondant sur plusieurs modalités d'établissement de la preuve afin d'accroître la crédibilité des constatations. Quand des stratégies distinctes qui sont fondées sur des sources de données et des méthodes d'analyse différentes aboutissent à la même conclusion, l'évaluateur peut raisonnablement les considérer comme fiables. Par contre, lorsqu'elles mènent à des conclusions différentes, la situation est évidemment beaucoup moins facile à trancher. Néanmoins, c'est un résultat préférable à ce qui se produit quand on se fonde sur une seule stratégie, en aboutissant sans s'en rendre compte à des conclusions qui pourraient être contradictoires pour peu qu'on en utilise une autre. Lorsque les conclusions diffèrent, c'est peut-être parce que les résultats du programme sont trop sensibles pour pouvoir être mesurés avec précision (ce qui signifie que l'erreur d'échantillonnage l'emporte sur l'effet incrémentiel); pour corriger le problème, il faut alors avoir recours à une meilleure méthode d'analyse ou recueillir plus de données, ou encore à une combinaison de ces deux approches.
Supposons par exemple qu'on tente d'évaluer les effets de notre fameux problème d'aide à un secteur d'activité industrielle. L'évaluation devrait porter sur l'effet incrémentiel du projet, ce qui reviendrait à essayer de déterminer si l'aide fournie a mené à la réalisation du projet envisagé. Cette question pourrait être étudiée sous plusieurs angles différents. Une stratégie consisterait à mener un sondage auprès des cadres des entreprises visées en leur posant la question directement ou indirectement. Cependant, pour diverses raisons, notamment parce qu'ils voudraient obtenir d'autres subventions, les répondants pourraient tendre à exagérer l'effet incrémentiel du programme. Il faudrait donc utiliser d'autres méthodes pour le déterminer. Par exemple, un examen détaillé des registres financiers et de marketing pour la période précédant immédiatement la mise en oeuvre du projet permettrait de juger si le rendement attendu des investissements justifiait son exécution sans l'aide de l'État. On pourrait aussi avoir recours à un modèle quasi expérimental avec une analyse correspondante comme nous le verrons au chapitre 3, pour comparer la réalisation de projets non subventionnés à celle de projets qui l'ont été, ou encore pour comparer la fréquence des projets exécutés avant et après la mise en oeuvre du programme.
Prenons aussi un autre exemple, celui des enquêtes postales qui peuvent avoir un très vaste rayonnement dans une population cible. Malheureusement, il s'agit là d'une stratégie qui ne se prête généralement pas à des études en profondeur, bien qu'elle puisse être renforcée grâce à des études de cas ou à des entrevues individuelles.
De même, les modèles implicites faisant appel à une analyse du contenu en soi sont peu fiables. Même si ces modèles sont utiles pour l'examen d'avantages difficiles à mesurer, il convient de les compléter par des stratégies plus fiables à fondement quasi expérimental, ce qui augmente énormément la crédibilité globale des constatations de l'évaluation.
Références : Stratégies multiples
Jorjani, Hamid, «The Holistic Perspective in the Evaluation of Public Programs : A Conceptual Framework», Canadian Journal of Program Evaluation, Vol. 9, No 2, octobre-novembre 1994, p. 71 à 92.
2.5 Résumé
Dans ce chapitre, nous avons analysé les aspects de la recherche et du contexte décisionnel dont il faut tenir compte pour l'élaboration et l'application de méthodes d'évaluation crédibles. Ce faisant, nous avons insisté sur la nécessité de ne jamais négliger les facteurs contextuels inhérents à toutes les études d'évaluation menées dans l'administration fédérale. Ces facteurs sont au moins aussi importants que les questions de recherche qui sont traditionnellement associées à une stratégie d'évaluation.
De plus, le présent chapitre décrit le bien-fondé de multiples éléments probants, soit le recours à plus d'une stratégie d'évaluation pour appuyer les inférences sur les effets du programme. Compte tenu des contraintes temporelles et financières on devrait toujours rechercher de multiples éléments probants pour appuyer les conclusions de l'évaluation.
- Date de modification :