Program Evaluation Methods
Archived information
Archived information is provided for reference, research or recordkeeping purposes. It is not subject à to the Government of Canada Web Standards and has not been altered or updated since it was archived. Please contact us to request a format other than those available.
Chapter 2 - EVALUATION STRATEGIES
This chapter begins by discussing the kinds of conclusions one can draw from an evaluation of a program's results. The chapter discusses, in general terms, the various "threats" that typically arise to the validity of an evaluation's conclusions. It then presents a conceptual framework for developing evaluation strategies. Finally, the need for employing multiple measurement strategies to generate credible conclusions is examined.
2.1 Causal Inference in Evaluation
Evaluation tries to establish what results were produced or caused by a program. This section attempts to clarify the meaning of statements concerning the causality of a program's results. The next section looks at the problems involved in trying to infer causality.
Consider first the kinds of results that might be caused by a program. In the simplest of cases, a program results in a positive change. This interpretation assumes, however, that without the program no change would be observed. This may not be the case. In the absence of the program, conditions might have improved or might have worsened. As well, a program may maintain the status quo by halting a deterioration that would have occurred otherwise. Establishing the incremental effect of the program is of vital importance.
Clearly, then, in order to understand what results were caused by a program, we need to know what would have happened had the program not been implemented. This concept is key to making causal inferences. Thus, by saying that a program produced or caused a certain result, we mean that if the program had not been in place, that result would not have occurred. But this interpretation of cause clearly applies more sensibly to some programs than to others. In particular, it applies to programs that can be viewed as interventions by government to alter the behaviour of individuals or firms through grants, services or regulations. It does make sense, and it is usually possible in these cases, to estimate what would have happened without a particular program.
Other programs, however (such as medical services, air traffic control and defence) are more sensibly thought of as ongoing frameworks within which society and the economy operate. These programs tend to exist where government has taken a lead role for itself. The programs are usually universal, so all members of society benefit from them. In economic terms, the results of these programs are considered "public goods." Difficulties arise when evaluating these programs because they are not amenable to an evaluation model that conceptualizes the program as a specific intervention. Such ongoing programs are typically too broad in scope for "traditional evaluation." There may be some exceptions to the rule; regardless, issues concerning the scope of the evaluation should be raised in the evaluation assessment for the client's consideration.
One final aspect of causality is critical if evaluation results are to be used for decision-making. It is only possible to generalize from the evaluation-determined results of a program if the program itself can be replicated. If the program is specific to a particular time, place or other set of circumstances, then it becomes problematic to draw credible inferences about what would happen if the program were implemented elsewhere under different circumstances.
2.2 Causal Inferences
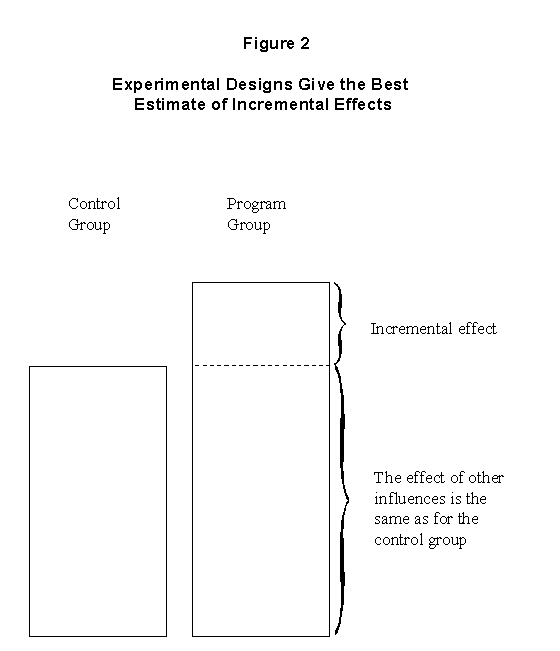
It is clear, conceptually, how one would make a causal inference: compare two situations that are identical in every respect, save for the program. Any difference between the two situations can be attributed to the program. This basic principle is illustrated in Figure 2: two identical groups of subjects (people, firms and schools) are selected; only one group (the experimental or treatment group) is subjected to the program; the other group (the control group) is subjected to all the same external influences as the experimental group, except for the program. The post-program outcome is measured the same way for both groups. At this point, any difference in outcome between the two groups can be attributed to the program, since the groups were initially identical and were exposed to the same external influences.
Unfortunately, in practice, the ideal design cannot be perfectly implemented since the perfect equivalence of the experimental and control groups can never be fully achieved. Different groups are made up of different subjects and hence must differ in some way even if average measures of a variable of interest are the same for both groups. Even if the same group is used for the experimental and control group, the observations with and without the program take place at different points in time, thus allowing additional influences to affect the observed post-program outcome.
Losing perfect equivalence weakens the validity of the causal inference, which makes it more difficult for decision-makers to assess past program performance and to use this performance as a guide for future programming decisions. This is compounded by the fact that government programs are only one of several factors influencing desired results. The rigour of the evaluation, and consequently its usefulness in the decision-making process, will depend on how closely it approximates the ideal design presented above.
The ability to infer that a program caused a certain result will depend, in practice, on the degree to which the evaluation is able to reject plausible alternative explanations, often referred to as "threats to the validity of the causal inference." Indeed, a typical evaluation will not lead to conclusive statements about causal linkages. Instead, the evaluation will reduce the uncertainty about such linkages while providing evidence to refute alternative linkages. The evaluation might, for example, produce evidence that the program is the most likely explanation of the observed result, and that other explanations have little supporting evidence. Or, it might be able to separate and quantify the effects of other contributing factors or possible explanations. Making causal inferences about results in evaluation means rejecting or accounting for rival plausible explanations.
Consider the previous example of an industrial grant program intended to create new jobs. If we observe a certain number of new jobs created by firms that get a grant, we would like to conclude that the jobs are the result of the program and that without the program, the new jobs would not have been created. Before such a conclusion can be reached, however, we must investigate a number of rival plausible explanations. It is possible, for example, that a general economic upturn created the new jobs. Or, it could be argued that the firms intended to create the jobs in any event, and the grants actually constituted a windfall transfer payment. These rival explanations and any other alternative explanations would have to be rejected, or their contribution accounted for, in order to determine the incremental effect of the program on job creation.
Eliminating or estimating the relative importance of rival explanations (threats to the validity of the hypothesized causal inference) is the major task of an evaluation that attempts to determine program outcomes. This is accomplished through a combination of assumption, logical argument and empirical analysis, each of which is referred to as an evaluation strategy in this publication.
Referring once again to our industrial grant program example, the threat to the validity of the conclusion posed by the economic upturn could be eliminated by establishing that there was no economic upturn in the general economy, in the firm's region or in the firm's particular sector of the economy. This could be accomplished by examining similar firms that did not receive grants. If new jobs were created only in those firms that received grants, this rival explanation of an economic upturn would be rendered implausible. If, on the other hand, it was observed that more new jobs were created in firms with grants than in those without, then the rival explanation could still be rejected and the difference in job creation between the two groups of firms could be attributed to the program (assuming, of course, that the two groups compared were reasonably similar). Note that by accounting for the effect of the economic upturn, this second finding alters the original conclusion that all new jobs were the result of the program. Furthermore, this comparison design, while not without limitations, rules out many other rival explanations, including the possibility that the firms would have created the jobs in any event. In this example, if only the two alternative explanations were thought to be likely, then on the above evidence, the conclusion that the additional jobs are due to the program would be fairly strong. As the next chapter discusses, however, it is more likely that the two groups of firms were not entirely similar, thus creating additional threats to the validity of the conclusions. When this is so, it is necessary to develop additional evaluation strategies to address these threats.
To this point we have been concerned with trying to determine the extent to which a program has caused an observed result. A further complicating factor exists. While it may be that the program is necessary for the result to occur, the program alone may not be sufficient. That is, the result may also depend on other factors, without which the result will not occur. Under such circumstances, the result will not occur without the program, but will not necessarily occur when the program is present. Here, all that can be inferred is that with the program and with the required factors in place, the result will occur.
These "required factors" will be of interest because, having arrived at some conclusion about an existing program's impact, there is typically an interest in generalizing the conclusion to other places, times or situations. This ability to generalize is known as the external validity of the evaluation and is limited to the assertion that under identical circumstances, implementing the program elsewhere would result in the same outcome. Of course, neither the conditions nor the program can be perfectly replicated, so such inferences are often weak and require further assumptions, logical arguments or empirical analysis to be rendered more credible. The use of multiple evaluation strategies can be useful here.
Returning to our industrial grant program example, what if one were to establish that in the presence of given marketing skills and other factors, the existing program did in fact create a certain number of jobs? This finding may be useful for accountability purposes, but it would be of limited use for future programming decisions. Programming questions typically revolve around whether to continue, contract or expand a program. The external validity of the conclusion, that a continued or expanded program would result in new jobs, would be threatened if the sample of firms studied was not representative of all the firms to which the program would apply, or if conditions that contributed to the success of the program are unlikely to be repeated. The remaining firms might not possess the requisite marketing skills, and the expanded program would therefore not have a similar impact on these firms. Thus, depending on the issue being examined and the type of decision to be made, one may wish to identify other explanatory factors and to explore the relationships between these factors and the program.
As with internal validity, various strategies are available to minimize the threats to external validity. Unfortunately, there will sometimes be a trade-off between the two. In formulating credible and useful conclusions for management to act on, the internal validity of the evaluation is important, but external validity issues cannot be ignored. Evaluators should be aware of the kinds of decisions that are to be made and hence the kinds of conclusions required. This, in turn, means being explicitly aware of the major threats to external validity that, if left unaddressed, could weaken the credibility and decision-making usefulness of the conclusions reached.
Summary
The problems associated with making causal inferences about programs and their results are one of the main foci of this publication. The other focus is the measurement of the results. Before arriving at conclusions about the effects of a program, the evaluator must first be aware of plausible alternative factors or events that could explain the results observed. Arguments must then be presented to refute these alternative explanations. So that the conclusions can be applied elsewhere, threats to external validity should be carefully monitored. Methods for determining program outcomes are appropriate to the extent that they produce the best evidence possible, within established time and resource limits.
References: Causal Inference
Campbell, D.T. and J.C. Stanley. Experimental and Quasi-experimental Designs for Research. Chicago: Rand-McNally, 1963.
Cook, T.D. and D.T. Campbell. Quasi-experimentation: Design and Analysis Issues for Field Settings. Chicago: Rand-McNally, 1979.
Cook, T.D. and C.S. Reichardt, eds. Qualitative and Quantitative Methods in Evaluation Research. Thousand Oaks: Sage Publications, 1979.
Heise, D.R. Causal Analysis, New York: Wiley, 1985.
Kenny, D.A. Correlation and Causality. Toronto: John Wiley and Sons, 1979.
Suchman, E.A. Evaluative Research: Principles and Practice in Public Service and Social Action Programs. New York: Russell Sage, 1967.
Williams, D.D., ed. Naturalistic Evaluation. V. 30 of New Directions in Program Evaluation. San Francisco: Jossey-Bass, 1986.V.
2.3 Evaluation Strategies
Two types of considerations must be borne in mind in developing methods for determining program results: research concerns (related to the quality of the evidence to be assembled) and concerns that arise from the decision environment in which the evaluation takes place. Both are important. However, there will be, to a degree, a trade-off between the scientific rigour and the decision-making relevance of the evaluation.
There are several ways of gathering evidence to determine the outcome of a program. This chapter presents the major evaluation strategies. Note that each of these will comprise an evaluation design (Chapter 3), a data collection method (Chapter 4) and an analysis technique (Chapter 5).
In our industrial assistance program example, one strategy to determine whether the program created jobs would be to survey the firms involved to ask them what would have occurred in the absence of the government grant. Another strategy would be to determine, again through survey analysis, the number of jobs created in similar firms, some of which received a grant and others which did not; and compare the results to measure for statistically significant differences. Yet another strategy might be to use in-depth case studies of firms that benefited from a grant to determine whether they would have created the jobs anyway. Each of these strategies addresses the same issue and each provides evidence of a different type and quality. Typically, no single strategy will offer definitive proof of the program's result. It will often be appropriate, therefore, to use several strategies. For example, there may be interest in determining the effect of the program on other issues, such as unfair competition resulting from the grants. This could be addressed in part by one of the above strategies and in part by a different strategy. The overall strategy settled upon would most likely comprise individual strategies designed to address specific sets of issues. Section 2.4.3 discusses the development of such multiple strategies or multiple lines of evidence.
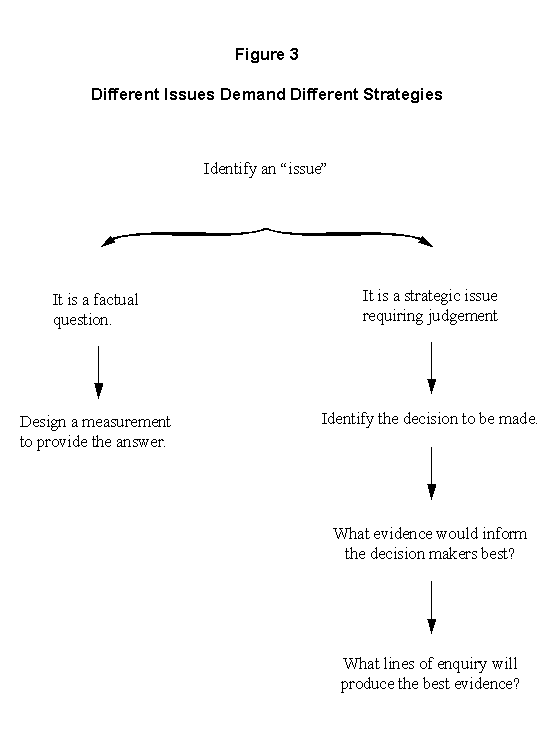
Figure 3 illustrates the general steps involved in developing evaluation strategies. It is useful to consider the development of an evaluation strategy as comprising a series of steps. The steps are described sequentially, but in practice the procedure is more iterative, since each step is closely linked to the others.
To begin with, the evaluator must select a design. The evaluation design is the logic model used to arrive at conclusions about outcomes. In selecting the evaluation design, the evaluator must determine simultaneously the type of information to be retrieved and the type of analysis this information will be subjected to. For example, to assess the extent to which a program has achieved a given objective, one must determine an indicator of this achievement and an analytic technique for isolating the effect of the program. Evaluation designs provide the logical basis for measuring results and for attributing results to programs.
Once the evaluation design is settled upon, the next stage is to choose specific methods and techniques for implementing the design, which means finding out what data will be necessary. The type of information required-qualitative or quantitative indicators of the achievement of stated objectives-is determined at the design stage. The next step is to define the data needed to obtain that information. Data are facts, things that can be observed and recorded. There are significant differences in the nature and quality of data. The evaluator's task is complicated by the fact that data vary in their accessibility, cost and timeliness. Deciding which data are most relevant and how to capture them raises the question of measurement. As will be seen later, measurement is a crucial methodological concern in evaluation.
Once data needs are identified, the potential sources of data must be examined. If reliable data cannot be obtained from a secondary source, primary data collection becomes necessary (Cook and Campbell, 1979, Chapter 1; Cronbach, 1982, Chapter 4). Primary data collection will generally cost more than simple reliance on secondary data and should therefore be avoided to the extent that it is possible to do so. A plan to acquire primary data typically involves selecting a collection technique (such as natural observation and mail surveys), developing measurement devices (such as questionnaires, interview guides and observation record forms) and developing a sampling plan.
Finally, depending on the type of analysis required and the type of data available, specific data analysis methods must be determined (such as cost-benefit, multiple regression, analysis of variance). The purpose of these analyses is to transform the data gathered into the required information for the evaluation.
2.4 Developing Credible Evaluations
Before we examine the specific elements of an evaluation strategy in detail, we should discuss the key concerns that must be addressed to develop a credible evaluation. Table 2 provides an outline of these concerns.
|
Table 2 - Considerations in Developing Credible Evaluation |
|---|
| Research Criteria |
measurement issues
|
| Decision Environment Criteria |
feasibility of formulating credible conclusions
|
2.4.1 Research Criteria
(a) Measurement Issues Many program effects are inherently difficult to measure. Consider the following:
- improvement in the well-being of elderly people through programs that enable them to continue functioning in their own homes;
- improvement in national security through the development of a major weapons system; and
- improvement in the incentives for carrying out industrial research and development through changes in the tax system.
All these, and many others, are effects that require both sophisticated measurement skills and in-depth expertise in a particular area of public policy.
Three aspects of measurement deserve careful consideration: reliability, measurement validity, and depth and breadth.
Reliability
A measurement is reliable to the extent that, repeatedly applied to a given situation, it consistently produces the same results. For instance, an IQ test would be reliable to the extent that, administered twice to the same person (whose intelligence has not changed) it produces the same score. In a program context, reliability can refer to the stability of the measurement over time or to the consistency of the measurement from place to place.
Unreliability may result from several sources. For example, it may arise from a faulty data collection procedure: If an interviewer does not read the interviewing instructions carefully, the results obtained may be somewhat different from those of interviewers who do so. As well, the measurement device or sampling plan could be unreliable. If the sampling procedure is not carried out properly, the sample is not likely to be representative of the population and, therefore, may yield unreliable conclusions.
Measurement validity
A measurement is valid to the extent that it represents what it is intended to represent. Valid measures (indicators) contain no systematic bias and capture the appropriate information. Do the data mean what we think they mean? Does the measurement technique indeed measure what it purports to measure? These issues are of critical importance in program evaluation.
Measurement validity problems can be conceptual or technical. Without careful thought, it is seldom clear which data best reflect the outcome to be measured. Too often, a decision is based solely on data that happen to be readily obtainable, but which yield measurements that are not as meaningful as might otherwise be obtained. Technical errors (such as measurement and sampling errors) may also occur, rendering the evaluation results inaccurate.
Depth and breadth
Related to the reliability and validity of measurements are the concepts of depth and breadth. Depending on the situation, one may wish to measure certain outcomes with great accuracy and others with less detailed accuracy but with several lines of evidence.
To measure the benefit of a program to an individual, in-depth interviewing and probing may be required. It may be necessary to have a number of different indicators, all reflecting different perspectives on the impact being considered. For example, in assessing the effect of an industrial assistance grant on a company, it may be necessary to look at resulting sales, changes in the number and quality of jobs, the effect of new machinery purchases on future competitiveness, and the like.
On the other hand, a target population for a program may be large and heterogeneous. Here, it may be appropriate for an evaluation to cover all parts of that population, but in less detail. To assess satisfactorily the industrial assistance program's effect on companies, one would have to ensure that the various types of firms targeted (large and small, from various sectors of the economy and different geographic regions) were adequately represented in the sample.
A major problem in dealing with the breadth and depth issue is that limited time and resources will usually force the evaluator to chose between the two. Breadth will lead to greater relevance and validity in terms of coverage. Typically, however, this will mean less depth, validity and reliability in measures of individual subjects.
(b) Attribution Issues
Often, a program is only one of many influences on an outcome. In fact, deciding how much of the outcome is truly attributable to the program, rather than to other influences, may be the most challenging task in the evaluation study.
The key to attribution is a good comparison. In laboratory settings, rigorously controlled comparison groups meet this need. In the case of federal government programs, less rigorous comparisons are generally possible and may be subject to many threats to internal validity and to external validity.
The following are the most common such threats to internal validity:
- History-events outside the program that affect those involved in the program differently than those in comparison groups;
- Maturation-changes in results that are a consequence of time rather than of the program (such as participant aging in one group compared with another group at a different stage);
- Mortality - respondents dropping out of the program (this might undermine the comparability of the experimental and control groups);
- Selection bias-the experimental and control groups are initially unequal in their propensity to respond to the program;
- Regression artefacts-pseudo-changes in outcomes occurring when people have been selected for the program on the basis of their extreme scores (any "extreme" group will tend to regress towards the mean over time, whether it has benefited from the program or not);
- Diffusion or imitation of treatment-respondents in one group become aware of the information intended for the other group;
- Testing-differences observed between the experimental and control groups may be due to greater familiarity with the measuring instrument in the treatment group; and
- Instrumentation-the measuring instrument may change between groups (as when different interviewers are used).
Several threats to external validity also exist, which means that there are limits to the appropriateness of generalizing the evaluation findings to other settings, times and programs. In the federal government context, external validity is always a major concern since evaluation findings are usually meant to inform future decision-making.
Three groups of threats to the ability to generalize findings exist:
- Selection and program interaction-effects on the program participants are not representative because of some characteristic of the people involved (that is important to effects) is not typical of the wider population;
- Setting and program interaction-the setting of the experimental or pilot program is unrepresentative of what would be encountered if the full program was implemented; and
- History and program interaction-the conditions under which the program took place are not representative of future conditions.
It is obviously very useful in selecting evaluation strategies to be aware of the likely threats to validity. Much of the ingenuity in evaluation design, and in the ensuing data collection and analysis, lies in devising ways of establishing the effects attributable to the program. One does this by setting up good comparisons that avoid as many threats to validity as possible.
For an evaluation focusing on results, designs differ mainly in how well they perform the task of establishing attributable program effects and, where appropriate, how readily the conclusions can be generalized. Designs are presented in Chapter 3 in descending order of credibility.
References: Research Design
Campbell, D.T. and J.C. Stanley. Experimental and Quasi-experimental Designs for Research. Chicago: Rand-McNally, 1963.
Cook, T.D. and D.T. Campbell. Quasi-experimentation: Designs and Analysis Issues for Field Settings. Chicago: Rand-McNally, 1979.
Kerlinger, F.N. Behavioural Research: A Conceptual Approach. New York: Holt, Rinehart and Winston, 1979, Chapter 9.
Mercer, Shawna L. and Vivek Goel. "Program Evaluation in the Absence of Goals: A Comprehensive Approach to the Evaluation of a Population-Based Breast Cancer Screening Program," Canadian Journal of Program Evaluation. V. 9, N. 1, April-May 1994, pp. 97-112.
Patton, M.Q., Utilization-focussed Evaluation, 2nd ed. Thousand Oaks: Sage Publications, 1986.
Rossi, P.H. and H.E. Freeman, Evaluation: A Systematic Approach, 2nd ed. Thousand Oaks: Sage Publications, 1989.
Ryan, Brenda and Elizabeth Townsend. "Criteria Mapping," Canadian Journal of Program Evaluation. V. 4, N. 2, October-November 1989, pp. 47-58.
Watson, Kenneth. "Selecting and Ranking Issues in Program Evaluations and Value-for-money Audits," Canadian Journal of Program Evaluation. V. 5, N. 2, October-November 1990, pp. 15-28.
2.4.2 Decision Environment Criteria
Given that evaluation is an aid to decision-making, the criteria for selecting an appropriate evaluation method must ensure that useful information is produced. This implies an understanding of the decision-making environment to which the evaluation findings will be introduced. More than technical questions about methodology are at issue here, though these remain of critical importance to the credibility of the evaluation's findings.
Developing an approach for evaluating program outcomes can become a very challenging task, one that involves more art than science. An appreciation of the technical strengths and weaknesses of various possible strategies for gathering evidence must be combined with an appreciation of the environment within which the evaluation takes place. This balancing must be done within the constraints imposed by limited resources and time. A combination of research and management experience is clearly required.
When evaluation approaches are being put together as options during the assessment (planning) stage, the question that should be repeatedly asked is "Will the recommended method (option) provide adequate evidence in relation to the issues of concern, on time and within budget?" Table 2 lists two decision-environment considerations to be kept in mind: the extent to which the method is likely to produce credible conclusions, and the extent to which the method is practical to implement. Each of these general considerations and associated issues is described below. Note that these considerations are relevant to all evaluation issues, not just those related to program outcomes.
(a) Formulating Credible Conclusions (Wise Recommendations on the Basis of Accurate Analysis)
-
The evaluation approach should consider the feasibility of formulating credible conclusions.
Evidence is gathered so that conclusions can be formulated about the issues addressed. The need is for objective and credible conclusions that follow from the evidence and that have enough supporting evidence to be believable. Coming up with such conclusions, however, can be difficult. The evaluator should be thinking of this when developing the evaluation strategy. Furthermore, credibility is, in part, a question of how the conclusions are reported: the believability of conclusions depends partly on how they are presented.
-
The evidence collected and conclusions reached should be objective, and any assumptions should be clearly indicated.
Objectivity is of paramount importance in evaluative work. Evaluations are often challenged by someone: a program manager, a client, senior management, a central agency or a minister. Objectivity means that the evidence and conclusions can be verified and confirmed by people other than the original authors. Simply stated, the conclusions must follow from the evidence. Evaluation information and data should be collected, analyzed and presented so that if others conducted the same evaluation and used the same basic assumptions, they would reach similar conclusions. This is more difficult to do with some evaluation strategies than with others, especially when the strategy relies heavily on the professional judgement of the evaluator. In particular, it should always be clear to the reader what the conclusions are based on, in terms of the evidence gathered and the assumptions used. When conclusions are ambiguous, it is particularly important that the underlying assumptions be spelled out. Poorly formulated conclusions often result when the assumptions used in a study are not stated.
-
The conclusions must be relevant to the decision environment and, in particular, must relate to the issues addressed.
During the course of a study, researchers sometimes lose sight of the original issues being addressed, making it difficult for the reader (the evaluation's client) to understand the relationship between the conclusions and the evaluation issues originally stated. Several potential reasons exist for this. It is possible, for instance, that the evaluation strategy was not well thought out beforehand, preventing valid evidence from being obtained on certain issues and preventing certain conclusions from being drawn. Alternatively, the interests of the evaluator could take over a study, resulting in inadequate attention to the concerns of senior management. Finally, additional issues may arise as the program and its environment are explored. However, this should cause no problem as long as the original issues are addressed and the additional issues and related conclusions are clearly identified as such.
-
The accuracy of the findings depends in large part on the level and type of evidence provided. The choice of the level and type of evidence should be made on the basis of contextual factors.
Two common problems in evaluative work are the frequent impossibility of coming up with definitive conclusions, and the incompleteness of the evidence provided by the individual strategies available.
In relation to the first problem, causal relationships between a program and an observed outcome often cannot be unequivocally proven, mainly because of the intractability of the measurement and attribution problems discussed earlier. Generally speaking, no single evaluation strategy is likely to yield enough evidence to answer unambiguously the questions posed by the evaluation.
This leads us directly to the second problem, the incompleteness of any single evaluation strategy. There are typically several possible evaluation strategies, each yielding a different level and type of evidence. The choice of strategies should be made on the basis of contextual factors related to the decisions about the program that have to be made-not solely on the basis of pre-set research considerations. The situation parallels that in law, where the type of evidence required depends on the seriousness and type of crime. Many civil actions require only probable cause, while more serious criminal actions require evidence "beyond a shadow of doubt" (Smith, 1981). Contextual factors that the evaluator should consider include the existing degree of uncertainty about the program and its results, the importance of the impact of the program, its cost, and the likelihood of challenges to any conclusions reached. The evaluator should be aware of any potential serious challenges to the conclusions and be ready to present appropriate counter-arguments.
The choice of the appropriate evidence to gather-and hence the choice of the evaluation method to use-is one the most challenging that the evaluator faces. Ideally, the client of the study, not the evaluator, will make the choice. The task of the evaluator is to present the client with various evaluation approaches which, among other things, offer a reasonable trade-off between the expected credibility of the conclusions and the cost and time of the evaluation method. In selecting an approach, the client should have a good understanding of what evidence will be produced, and therefore be able to judge whether the rigour of the evaluation will be appropriate to the decisions that will follow. The evaluator should, of course, develop possible approaches that reflect the known decision environment, hence making it easier for the client to decide.
-
The conclusions reached should be based on a comprehensive coverage of the relevant issues.
Comprehensiveness, or the lack thereof, is another common problem in evaluative work. (Though comprehensiveness falls under the issue of appropriate evidence, it is listed separately in Table 2 because it is common to produce objective and appropriate evidence on most of the issues of concern, but to leave others inadequately explored or ignored altogether.) This is a macro-measurement concern. The evaluator should try to get as accurate a picture as possible of the issue from the client's perspective. This includes exploring all issues of concern that time and financial resource constraints allow. (Remember that where the federal government is concerned, the "client" is, ultimately, the Canadian public.) Breadth may be difficult to achieve at times, but if it is sacrificed for greater depth of analysis in the remaining issues covered, there is a real danger that the conclusions reached will be narrowly accurate but lacking in perspective. This danger can usually be avoided by discussing the evaluation issues with both the client and others holding varying views. An appropriately broad evaluation strategy will likely follow from this process.
If the evaluator views the task as a means of providing additional relevant information about a program and its outcome (that is, as a method for reducing uncertainty about a program), rather than as producing conclusive proof of the effectiveness of the program, then more useful conclusions will likely result. Pursuing evidence while bearing this purpose in mind, the evaluator is likely to face difficult trade-offs between relevance and rigour. Evaluation methods will be chosen to maximize the likelihood of arriving at useful conclusions, even if the conclusions are qualified.
-
Finally, a clear distinction should be drawn between the evaluation's findings and recommendations.
Evaluators may frequently be called on to provide advice and recommendations to the client of the study. In these instances, it is crucial that a distinction be maintained between findings derived from the evidence produced by the study, and program recommendations derived from the evaluation conclusions or from other sources of information, such as policy directives. The evaluation's conclusions will lose credibility when this distinction is not maintained.
For example, the findings of an evaluation on a residential energy conservation program may allow the evaluator to conclude that the program has successfully encouraged householders to conserve energy. However, information obtained from sources other than the evaluation may indicate that other conservation programs are more cost effective, and the evaluator is therefore prompted to recommend that the program be discontinued. In this case, the evaluator must clearly indicate that the recommendation is not based on information obtained from the evaluation, but rather on information obtained externally.
(b) Practical Issues
-
In developing an evaluation method, the evaluator must take into account basic considerations such as practicability, affordability and ethical issues.
An approach is practicable to the extent that it can be applied effectively without adverse consequences and within time constraints. Affordability refers to the cost of implementing the approach. Implementing the method most appropriate to a given situation might be unrealistically expensive. An evaluation method must be able to handle measurement and attribution problems, to allow for credible conclusions and, at the same time, to be implemented within the resources allocated.
Ethical considerations (moral principles or values) must be assessed in developing an evaluation method. It may not be ethical to apply a program to only a subset of a given population. For example, ethical considerations would arise if an evaluation of a social service program is to be based on randomly selecting a group of recipients and withholding services from other equally deserving recipients. Specific ethical considerations for evaluation in the Government of Canada are embodied in various provisions of government policy concerning the collection, use, preservation and dissemination of information. These include the Access to Information Act, the Privacy Act, the Statistics Act, and Treasury Board's Government Communications Policy and its Management of Government Information Holdings Policy. The latter policy deals in part with procedures to minimize unnecessary data collection and to ensure a prior methodological review of data collection activities.
References: The Decision Environment
Alkin, M.C. A Guide for Evaluation Decision Makers. Thousand Oaks: Sage Publications, 1986.
Baird, B.F. Managerial Decisions under Uncertainty. New York: Wiley Interscience, 1989.
Cabatoff, Kenneth A. "Getting On and Off the Policy Agenda: A Dualistic Theory of Program Evaluation Utilization," Canadian Journal of Program Evaluation. V. 11, N. 2, Autumn 1996, pp. 35-60.
Ciarlo, J., ed. Utilizing Evaluation. Thousand Oaks: Sage Publications, 1984.
Goldman, Francis and Edith Brashares. "Performance and Accountability: Budget Reform in New Zealand," Public Budgeting and Finance. V. 11, N. 4, Winter 1991, pp. 75-85.
Mayne, John and R.S. Mayne, "Will Program Evaluation be Used in Formulating Policy?" In Atkinson, M. and M. Chandler, eds. The Politics of Canadian Public Policy. Toronto: University of Toronto Press, 1983.
Moore, M.H. Creating Public Value: Strategic Management in Government. Boston: Harvard University Press, 1995.
Nutt, P.C. and R.W. Backoff. Strategic Management of Public and Third Sector Organizations. San Francisco: Jossey-Bass, 1992.
O'Brecht, Michael. "Stakeholder Pressures and Organizational Structure," Canadian Journal of Program Evaluation. V. 7, N. 2, October-November 1992, pp. 139-147.
Peters, Guy B. and Donald J. Savoie, . Canadian Centre for Management Development. Governance in a Changing Environment. Montreal and Kingston: McGill-Queen's University Press, 1993.Pressman, J.L. and A. Wildavsky. Implementation. Los Angeles: UCLA Press, 1973.
Reavy, Pat, et al. "Evaluation as Management Support: The Role of the Evaluator," Canadian Journal of Program Evaluation. V. 8, N. 2, October-November 1993, pp. 95-104.
Rist, Ray C., ed. Program Evaluation and the Management of the Government. New Brunswick, NJ: Transaction Publishers, 1990.
Schick, Allen. The Spirit of Reform: Managing the New Zealand State. Report commissioned by the New Zealand Treasury and the State Services Commission, 1996.
Seidle, Leslie. Rethinking the Delivery of Public Services to Citizens. Montreal: The Institute for Research on Public Policy (IRPP), 1995.
Thomas, Paul G. The Politics and Management of Performance Measurement and Service Standards. Winnipeg: St.-John's College, University of Manitoba, 1996.
2.4.3 The Need for Multiple Strategies
While an evaluation strategy yields evidence about a result, an evaluation study generally addresses several issues at a time and hence benefits from the pursuit of a number of evaluation strategies. As well, it may be desirable to employ more than one strategy to address a given issue since this will increase the accuracy and credibility of the evaluation findings.
Most evaluation strategies developed to address one issue can, with some modification, be expanded to cover additional issues. Even if a strategy is not optimal for addressing an additional issue, it might nevertheless be usefully pursued due to its low marginal cost. For example, suppose a study investigated the reading achievements of two groups, one of which was participating in a given program. Assume individuals in each group are given a test to measure reading achievement and are also asked some questions about the usefulness and effectiveness of the program. These latter results suffer from the weaknesses inherent in all attitudinal survey results, yet they add relatively little cost to those already incurred in administering the reading achievement test.
The second reason to consider several evaluation research strategies is that it is often desirable to measure or assess the same result based on a number of different data sources, as well as through a number of different evaluation designs. It is often difficult, if not impossible, to measure precisely and unambiguously any particular result. Confounding factors, errors in measurement and personal biases all lead to uncertainty about the validity or reliability of results derived from any one analytical technique. A given evaluation design is usually open to several threats to internal validity; alternative explanations cannot be entirely ruled out or accounted for. Consequently, complementary strategies can be an effective means of ruling out rival explanations for observed outcomes.
For the above two reasons, it is desirable to address evaluation issues from a number of different perspectives, using multiple lines of evidence to lend greater credibility to the evaluation findings. When independent strategies relying on different data sources and different analytical techniques converge on the same conclusion, the evaluator can be reasonably confident that the conclusions are reliable. Of course, if individual strategies lead to varying conclusions, the situation is somewhat problematic. Nevertheless, this result is preferable to carrying out a single strategy and unknowingly drawing conclusions that would be contradicted by a different strategy. Where conclusions differ, it could mean that program impacts are too small to be measured accurately (i.e. the sampling error is greater than the incremental effect); a finer analytical technique, more data or some combination of the two might remedy the situation.
Consider, for instance, an attempt to assess the effects of our oft-used industrial assistance program example. The evaluation would examine the incremental effect of the project; did the assistance cause the project to proceed? This issue could be addressed in a number of different ways. One strategy would be to survey corporate executives, posing the question directly or indirectly. However, for a number of different reasons, including a desire for further government funding, respondents might tend to exaggerate the incremental effect of the program. This problem would indicate the need to investigate incremental effects in other ways. For instance, a detailed examination of financial and marketing records from before the project began might indicate whether the expected return on investment justified going ahead without government aid. It might also be possible to use a quasi-experimental design and analysis (see Chapter 3) to compare the occurrence of non-funded projects that were similar to the funded projects, or the frequency of projects before and after the program began.
As another example, consider the use of mail-out surveys, a technique that can yield broad coverage of a target population. Unfortunately, this strategy generally lacks depth. However, it can be useful to buttress findings derived through case studies or in-depth personal interviews.
Similarly, an implicit design using content analysis is, by itself, unreliable. Although this strategy may address hard-to-measure benefits, it best used in conjunction with more reliable (quasi-experiment-based) strategies. Combining strategies this way adds greatly to the overall credibility of the evaluation findings.
References: The Need for Multiple Strategies
Jorjani, Hamid. "The Holistic Perspective in the Evaluation of Public Programs: A Conceptual Framework," Canadian Journal of Program Evaluation. V. 9, N. 2, October-November 1994, pp. 71-92.
This chapter discussed the research and decision environment elements that one must consider when developing and implementing a credible evaluation methodology. It stressed the need to take into account the contextual factors associated with any evaluation study in the federal government. These factors are at least as important as the traditional research considerations associated with an evaluation strategy.
As well, this chapter outlined the desirability of using multiple lines of evidence; that is, using more than one evaluation strategy to support inferences on program impact. To the extent that time and money constraints allow, multiple lines of evidence should always be sought to support evaluation findings.
- Date modified: