Méthodes d'évaluation des programmes
Informations archivées
Les informations archivées sont fournies aux fins de référence, de recherche ou de tenue de documents. Elles ne sont pas assujetties aux normes Web du gouvernement du Canada et n’ont pas été modifiées ou mises à jour depuis leur archivage. Pour obtenir ces informations dans un autre format, veuillez communiquez avec nous.
Chapitre 5 - MÉTHODES ANALYTIQUES
5.1 Introduction
Les méthodes analytiques utilisées pour l'évaluation devraient être clairement exposées à l'étape du choix du modèle. Il ne faudrait jamais recueillir de données à moins que l'évaluateur sache exactement comment elles seront utilisées dans l'analyse. Un bon modèle d'évaluation tiendra compte de trois éléments : les questions à l'étude, les méthodes d'analyse et les données susceptibles d'être recueillies. Toutes ces pièces doivent se combiner parfaitement avant que l'évaluation commence.
Dans ce chapitre, nous allons décrire les méthodes analytiques utilisées dans l'administration fédérale pour déterminer les résultats d'un programme. Notre démarche est axée sur l'utilisation de ces méthodes en tant qu'éléments d'une stratégie d'évaluation donnée. Évidemment, elles peuvent aussi être utiles pour d'autres parties de l'évaluation. Par exemple, l'étude préparatoire comporte habituellement une analyse exploratoire qui contribue à cerner les questions à l'étude et à définir les méthodes de recherche les plus utiles. En outre, l'analyse permet d'intégrer les constatations obtenues grâce aux différentes stratégies d'évaluation.
Dans les pages qui suivent, nous allons décrire à la fois l'analyse de la mesure directe des répercussions des programmes ainsi que celle qui fait appel aux mesures de ces répercussions directes pour produire une estimation de diverses retombées des programmes. On distingue deux types de méthodes d'analyse directe, les méthodes statistiques et les méthodes non statistiques. Nous allons compléter ces descriptions avec celle de diverses méthodes d'analyse indirecte.
5.2 Analyse statistique
L'analyse statistique implique la manipulation de données (catégoriques) quantitatives ou qualitatives en vue de décrire des phénomènes et de procéder à des inférences quant aux relations entre variables. Les données en question peuvent être soit objectives et «concrètes», soit subjectives et «abstraites», mais les unes et les autres doivent être décrites ou organisées de façon systématique. Presque toutes les études analytiques font appel à l'analyse statistique, mais son emploi exige de la compétence et une compréhension des hypothèses sous-jacentes.
L'analyse statistique a deux raisons d'être, la première consistant à faire une description, ce pourquoi on utilise des tableaux statistiques afin de présenter des données quantitatives et qualitatives de façon aussi succincte que révélatrice. La seconde raison d'être des modèles statistiques consiste à faire des inférences pour vérifier les rapports entre les variables étudiées ou pour généraliser des constatations en les appliquant à une population plus étendue (d'après l'échantillon).
Pour faire rapport des constatations d'une étude d'évaluation, il faut souvent présenter succinctement une grande quantité de données. Les statistiques, présentées sous forme de tableau ou de graphique et de «statistiques» (comme la moyenne ou la variance) peuvent faire ressortir les principales caractéristiques des données.
Pour illustrer l'utilisation de l'analyse statistique descriptive, prenons l'exemple d'un programme d'enseignement de la langue seconde pour lequel on a évalué les connaissances des immigrants avant et après leur participation. Le tableau 3 contient deux exemples (A et B) de présentation sommaire des résultats aux examens des participants. Les deux sont des résumés descriptifs des données. Le second exemple (B) est plus ventilé (moins succinct) que le premier (A), dans lequel on présente la note moyenne (c.-à -d. la moyenne arithmétique des résultats). Cette statistique peut correspondre à un résultat moyen sans contenir de précisions sur l'étendue ou la distribution des résultats. Comme on peut le constater, la note moyenne des 43 personnes qui ont suivi tout le programme a été de 64,7 p. 100, comparativement à une note moyenne avant le programme de 61,2 p. 100.
|
Tableau 3 - Exemple de statistiques descriptives |
|||||||||
| A) Présentation des résultats moyens | |||||||||
|
Résultat |
Nombre de personnes ayant passé l'examen |
||||||||
| Examen antérieur au programme |
61,2 |
48 |
|||||||
| Examen postérieur au programme |
64,7 |
43 |
|||||||
| B) Présentation de la distribution des résultats | |||||||||
|
0-20 |
21-40 |
41-60 |
61-80 |
81-100 |
N |
||||
| Examen antérieur au programme |
|
|
|
|
|
|
|||
|
Écart type = 22,6 |
|||||||||
| Examen postérieur au programme |
|
|
|
|
|
|
|||
|
Écart type = 23,7 |
|||||||||
Par contre, dans le second exemple (B), la distribution générale des notes est présentée à partir des mêmes données brutes que celles utilisées pour le premier exemple (A). Ainsi, à l'évaluation antérieure au programme, six des participants avaient obtenu une note de 0 à 20 % et 20 autres une note de 61 à 80 %. La distribution des notes peut aussi être exprimée en pourcentages : on voit ainsi que 50 p. 100 (24/48) des participants évalués avant le programme avaient obtenu une note variant entre 61 et 80 %, alors que 16,3 p. 100 (7/43) de ceux qui l'ont été après le programme ont obtenu une note entre 81 et 100 %. Cette présentation en pourcentages fournit aussi des descriptions plus globales des données (par exemple, on constate que 60,4 p. 100 des participants évalués avant le programme ont obtenu plus de 60 % à l'examen.
Enfin, une statistique telle que l'écart type peut servir à résumer l'étendue de la distribution. L'écart type correspond à la mesure dans laquelle les résultats individuels se rapprochent de la moyenne arithmétique, c'est-à -dire de la normale. Plus l'écart type est petit par rapport à la normale, moins la distribution est étendue.
Les tableaux ne sont pas la seule façon de présenter des statistiques descriptives. On peut aisément présenter des données et des statistiques sous forme de graphiques. Les graphiques à barre sont utilisés pour les distributions, tandis que les graphiques circulaires ou les boîtes illustrent des proportions relatives. Ces présentations visuelles, faciles à produire avec des logiciels statistiques, peuvent être très utiles pour résumer des données statistiques, puisqu'elles sont souvent plus faciles à lire qu'un tableau et n'exigent pas nécessairement une compréhension de tous les aspects des statistiques pour en tirer une information utile.
Comme nous l'avons déjà indiqué, les données subjectives (fondées sur les attitudes) peuvent être traitées de la même façon que les données objectives. Supposons qu'on demande aux participants à un programme de formation d'évaluer leurs progrès sur une échelle de 1 à 5. Les résultats pourraient être présentés comme suit :
|
1 |
2 |
3 |
4 |
5 |
Nombre |
|
| Nombre de répondants |
16 |
38 |
80 |
40 |
26 |
200 |
| Pourcentage |
8 % |
19 % |
40 % |
20 % |
13 % |
|
| Résultat moyen : 3,1 | ||||||
Dans ce cas-ci, on voit que 40 des 200 répondants (20 p. 100) ont évalué leurs progrès à 4 sur 5. La moyenne était de 3,1. Bien sûr, on peut contester la fiabilité et la validité de cette technique de mesure, mais il n'en reste pas moins que l'évaluateur peut s'en servir pour résumer succinctement les 200 réponses grâce à une simple analyse statistique descriptive.
La deuxième principale raison de l'analyse statistique consiste à faire des inférences,c'est-à -dire à tirer des conclusions sur des rapports entre variables, puis à généraliser ces conclusions pour les appliquer dans d'autres situations. Dans l'exemple du tableau 3, si nous supposons que les personnes qui ont subi des examens avant et après leur participation au programme sont un échantillon d'une population plus nombreuse, il faut déterminer si l'amélioration des résultats est réelle et attribuable au programme (ou à d'autres facteurs accessoires), ou si elle est simplement attribuable aux éléments aléatoires de l'échantillon, autrement dit à une erreur d'échantillonnage. Or, grâce à des méthodes statistiques comme l'analyse de la variance, il est possible de déterminer si les résultats moyens sont statistiquement différents.
À cet égard, il convient de souligner que tout ce qui est établi dans ce cas, est un rapport, à savoir que le résultat obtenu après la participation au programme est supérieur à celui qui l'avait été avant. Pour conclure que cette amélioration est attribuable au programme, il faut tenir compte des obstacles à la validité interne qui ont été analysés aux chapitres 2 et 3. Les vérifications statistiques telles que l'analyse de la variance montrent simplement qu'il existe une différence statistiquement significative entre le résultat obtenu avant le programme et celui constaté après. Les vérifications statistiques ne prouvent donc pas que la différence est attribuable au programme. D'autres vérifications statistiques et des données supplémentaires peuvent aider à répondre aux questions d'attribution.
Prenons un autre exemple de rapports établis entre des variables grâce à une analyse statistique, soit celui des données présentées au tableau 4. Nous y voyons les résultats (en pourcentages) obtenus avant et après la participation au programme par des hommes et des femmes. Ces statistiques descriptives peuvent révéler les effets différents d'un programme pour divers groupes de participants. Ainsi, la première partie du tableau 4 montre que l'écart entre les résultats avant et après le programme est minime pour les hommes. Il s'ensuit que les descriptions laissent entendre que le programme a eu des effets différents selon le groupe de participants. Ces différences peuvent être des indices importants qu'il conviendrait de mener d'autres vérifications pour déterminer leur importance statistique.
Lorsqu'on étudie les données présentées aux tableaux 3 et 4, on voit que l'évaluateur pourrait avoir recours à l'analyse statistique par inférence pour estimer la force du rapport apparent, à savoir que les femmes ont obtenu de meilleurs résultats que les hommes. Des méthodes statistiques telles que l'analyse de régression (ou l'analyse loglinéaire) pourraient servir à établir l'importance de la corrélation entre les variables à l'étude. Dans ce cas-ci, le rapport entre les résultats, la participation ou la non-participation au programme et le sexe du participant pourrait être déterminé. En effet, les techniques statistiques de ce genre peuvent contribuer à déterminer l'importance des rapports entre les résultats d'un programme et les caractéristiques de ses participants.
Il est à noter que, même si les techniques statistiques dont nous venons de traiter (comme l'analyse de régression) sont souvent associées à l'analyse statistique par inférence, de nombreuses statistiques descriptives sont aussi produites dans ce contexte. L'évaluateur devrait établir une distinction entre le procédé arithmétique associé par exemple à l'estimation d'un coefficient de régression et la méthode à utiliser pour en évaluer l'importance. Il s'agit dans le premier cas d'une description et dans le second d'une inférence. Cette distinction est particulièrement importante lorsqu'on utilise un logiciel statistique pour produire de nombreuses statistiques descriptives. En effet, l'évaluateur doit faire des inférences appropriées à partir de ces statistiques-là .
|
Tableau 4 - Autres données descriptives |
|||||
| Distribution des résultats selon le sexe | |||||
|
HOMMES |
|||||
|
0-20 |
21-40 |
41-60 |
61-80 |
81-100 |
|
| Examen passé avant le programme |
|
|
|
|
|
| Examen passé après le programme |
13 % |
14 % |
33 % |
22 % |
18 % |
|
FEMMES |
|||||
| Examen passé avant le programme |
|
|
|
|
|
| Examen passé après le programme |
8 % |
4 % |
23 % |
42 % |
23 % |
L'analyse statistique peut aussi servir à généraliser à une population plus nombreuse des constatations associées à un groupe donné. Il se peut par exemple que les résultats moyens obtenus aux examens avant et après la participation au programme qui sont présentés au tableau 3 soient représentatifs de l'ensemble de la population des immigrants, à condition qu'on ait utilisé des techniques d'échantillonnage appropriées ainsi que des méthodes statistiques acceptables pour établir les estimations. Si le groupe évalué était suffisamment important et statistiquement représentatif de l'ensemble de la population des immigrants, on devrait pouvoir s'attendre à obtenir des résultats semblables si le programme devait prendre de l'ampleur. Bien exécutée, l'analyse statistique peut donc grandement améliorer la validité externe des conclusions.
Les méthodes statistiques varient selon le niveau des mesures appliqué aux données (catégorique, ordinal, intervalle et rapport) ainsi que selon le nombre de variables en jeu. Les méthodes paramétriques sont fondées sur l'hypothèse que les données sont dérivées d'une population ayant une distribution normale (ou une autre distribution quelconque). D'autres méthodes «robustes» permettent toutefois à l'évaluateur de s'écarter fortement des hypothèses de normalité. Par exemple, on peut utiliser un grand nombre de méthodes non paramétriques (sans distribution) pour les données ordinales.
Les méthodes à variable unique portent sur le rapport statistique entre une variable et une autre, alors que les méthodes à plusieurs variables sont conçues pour déterminer le rapport entre une ou plusieurs variables et un autre ensemble d'au moins deux variables.
Les méthodes à plusieurs variables peuvent être utilisées par exemple pour dégager des tendances, faire des comparaisons justes, préciser des comparaisons et étudier l'influence marginale d'une variable (les effets des autres facteurs restant constants).
On distingue deux types de méthodes à plusieurs variables, celles qui sont fondées sur le modèle linéaire général (c.-à -d. le modèle paramétrique normal), et celles, plus modernes, qu'on utilise pour l'analyse de plusieurs variables de données catégoriques, comme l'analyse loglinéaire. On peut aussi les répartir en deux catégories :
- a) méthodes servant à l'analyse de la dépendance, telles que les méthodes de régression (y compris l'analyse de la variance/covariance), la représentation fonctionnelle, l'analyse de trajectoires, les méthodes à série temporelle et à contingences multiples, ainsi que les méthodes qualitatives (catégoriques) et mixtes;
- b) méthodes utilisées pour l'analyse de l'interdépendance, telle que l'analyse typologique, l'analyse des composantes principales, la corrélation canonique et les analogues catégoriques.
Avantages et inconvénients
-
L'analyse statistique permet de résumer les constatations d'une évaluation de façon claire, précise et fiable; c'est aussi une technique valide de détermination de la valeur statistique attribuable aux conclusions que l'évaluateur tire des données.
En dépit de ses nombreux avantages, l'analyse statistique présente plusieurs inconvénients.
-
Il faut être compétent pour réaliser une bonne analyse statistique.
L'évaluateur devrait consulter un statisticien professionnel aux étapes de la conception et de l'analyse de son évaluation. Il faudrait éviter de se laisser séduire par la facilité apparente de la manipulation statistique à l'aide de logiciels standard.
-
Les résultats d'un programme ne peuvent pas tous être analysés par des méthodes statistiques.
Par exemple, les réponses à une question ouverte sur les résultats d'un programme peuvent renfermer de longues descriptions des avantages et des répercussions néfastes du programme, alors qu'il peut être très difficile de classer - et plus encore de quantifier - ces réponses d'une façon qui se prête à l'analyse statistique sans perdre des nuances importantes, quoique subtiles.
-
La façon de classer les données peut tout aussi bien fausser les résultats que révéler d'importantes différences.
Même lorsque l'évaluateur a obtenu des données quantitatives, il devrait interpréter avec soin les résultats des analyses statistiques. Ainsi, les données figurant au tableau 3 pourraient être représentées d'une façon différente, comme on le voit au tableau 5. Au départ, les données sont identiques, mais les résultats présentés au tableau 5 semblent révéler un effet beaucoup plus marqué que ceux du tableau 3. Cet exemple montre bien l'importance d'utiliser des méthodes statistiques supplémentaires pour vérifier la solidité des rapports apparents. En d'autres termes, avant de conclure que les différences apparentes entre le tableau 3 ou le tableau 5 sont des résultats du programme, il faudrait pousser plus loin l'analyse statistique inférencielle.
|
Tableau 5 -Exemple de statistiques descriptives |
||||
| A) Présentation des résultats moyens | ||||
| Examen antérieur au programme |
58,4 |
|||
| Examen postérieur au programme |
69,3 |
|||
| B) Présentation de la distribution des résultats | ||||
|
0-35 |
36-70 |
71-100 |
N |
|
| Examen antérieur au programme |
10 |
28 |
10 |
48 |
| Examen postérieur au programme |
6 |
11 |
26 |
43 |
-
Les praticiens qui se servent de l'analyse statistique doivent connaître aussi bien les hypothèses sur lesquelles la technique statistique employée est fondée que ses limites.
Une des grandes difficultés d'utilisation des méthodes analytiques, c'est que leur validité est fonction des hypothèses fondamentales qu'elles posent sur les données. Compte tenu de la grande disponibilité de logiciels statistiques, on court toujours le risque que les techniques utilisées fassent appel à des données qui doivent présenter certaines caractéristiques que les données auxquelles on a accès n'ont pas. Bien entendu, cela peut mener à des conclusions injustifiées. Par conséquent, il est essentiel que l'évaluateur connaisse les limites des techniques qu'il emploie.
-
Les méthodes statistiques à plusieurs variables sont particulièrement vulnérables à ce genre d'abus, même si elles peuvent donner l'impression d'avoir bien été utilisées. Pour que lesdites méthodes soient acceptables, il faut que le modèle causal sous-jacent soit correctement spécifié.
-
La régression à plusieurs variables peut notamment faire tomber l'évaluateur dans les pièges suivants :
- fournir tant d'explications qu'une différence réelle est éliminée;
- ajouter des éléments superflus à un schéma simple;
- susciter un optimisme exagéré quant à la solidité des rapports de causalité établis à partir des données;
- utiliser une méthode analytique incorrecte.
Références : Analyse statistique
Behn, R.D. et J.W. Vaupel, Quick Analysis for Busy Division Makers, New York : Basic Books, 1982.
Casley, D.J. et K. Kumar, The Collection, Analysis and Use of Monitoring and Evaluation Data, Washington (DC) : Banque mondiale, 1989.
Fienberg, S., The Analysis of Cross-classified Categorical Data (2e édition), Cambridge (MA) : Massachusetts Institute of Technology (MIT), 1980.
Hanley, J.A., «Appropriate Uses of Multivariate Analysis,» Annual Review of Public Health, Palo Alto (CA) : Annual Reviews Inc., 1983, p. 155 à 180.
Hanushek, E.A. et J.E. Jackson, Statistical Methods for Social Scientists, New York : Academic Press, 1977.
Hoaglin, D.C., et al., Data for Decisions, Cambridge (MA) : Abt Books, 1982.
Morris, C.N. et J.E. Rolph, Introduction to Data Analysis and Statistical Inference, Englewood Cliffs (NJ) : Prentice Hall, 1981.
Ragsdale, C.T., Spreadsheet Modelling and Decision Analysis, Cambridge, (MA) : Course Technology Inc., 1995.
5.3 Analyse de l'information qualitative
L'analyse non statistique est surtout appliquée à des données qualitatives, telles que les descriptions détaillées des dossiers administratifs ou des journaux d'observation sur le terrain, les affirmations directes en réponse à des questions ouvertes, la transcription de discussions en groupe et les observations de toutes sortes dont il a été brièvement question aux sections 4.1 et 4.4 à 4.7. Dans la présente section, nous nous bornerons à une description succincte de l'analyse non statistique. Pour obtenir des précisions à ce sujet, le lecteur est prié de consulter les références citées à la fin de la section.
L'analyse de données qualitatives, qui se fait ordinairement de pair avec l'analyse statistique et d'autres types d'analyses de données quantitatives, peut donner un aperçu holistique des phénomènes étudiés dans le contexte de l'évaluation. La collecte et l'analyse de l'information qualitative sont souvent «naturalistes» et fondées sur des déductions. Au début de l'étape de collecte des données ou de l'analyse, l'évaluateur ne s'appuie sur aucune théorie particulière à l'égard des phénomènes à l'étude. (Un autre type d'analyse non statistique de données quantitatives est décrit à la section 5.5 qui porte sur l'utilisation de modèles.)
Il est possible que l'analyse non statistique de données fasse davantage appel au jugement professionnel de l'évaluateur que d'autres méthodes, comme l'analyse statistique. Il s'ensuit qu'en plus de devoir bien connaître les questions qui font l'objet de l'évaluation, l'évaluateur qui effectue une analyse non statistique doit être conscient des nombreux biais qui sont susceptibles de fausser ses constatations.
Il y a plusieurs types d'analyse non statistique, dont l'analyse du contenu, l'analyse des études de cas, l'analyse inductive (y compris l'établissement de typologies) et l'analyse logique. Toutes ces méthodes sont censées faire ressortir des constantes, des thèmes, des tendances et des «motifs» des données, en plus de fournir des interprétations et des explications de ces constantes et de ces autres éléments. L'analyse des données devrait évaluer la fiabilité et la validité des constatations, par exemple grâce à une étude des hypothèses contradictoires, et elle devrait aussi analyser les cas «déviants» ou exceptionnels et faire une «triangulation» en comparant des données tirées de plusieurs sources ou obtenues grâce à d'autres méthodes de collecte et d'analyse.
Les quatre principales décisions à prendre dans le contexte d'une analyse non statistique de données portent sur la méthode analytique (résumé qualitatif, comparaison qualitative ou analyse statistique descriptive ou à plusieurs variables), sur le niveau de l'analyse, sur le moment auquel il convient de la faire, ce qui suppose des décisions quant à l'enregistrement et au codage des données ainsi qu'à l'opportunité de les quantifier, et enfin sur la façon d'intégrer l'analyse non statistique à l'analyse statistique connexe.
Bien que l'analyse non statistique (et statistique) des données suit normalement leur collecte, les deux peuvent se faire simultanément. Cette façon de procéder peut permettre à l'évaluateur de poser de nouvelles hypothèses qu'il peut vérifier aux étapes ultérieures de la collecte des données, ainsi que de cerner et de corriger d'éventuelles difficultés à cet égard, de même que d'obtenir l'information qui semble faire défaut dans les données recueillies au début. Par contre, les conclusions fondées sur une analyse hâtive risquent de biaiser la collecte ultérieure des données, voire de provoquer un changement prématuré de la conception ou de l'exécution du programme, ce qui rend bien délicate l'interprétation des constatations fondées sur toute la gamme des données recueillies.
Il est préférable de combiner l'analyse non statistique des données avec une analyse statistique de données connexes (quantitatives ou qualitatives). À cette fin, il faudrait concevoir l'évaluation de façon à ce que les deux sortes d'analyses pour lesquelles on utilise des données différentes mais connexes s'appuient, ou du moins s'éclairent mutuellement.
Avantages et inconvénients
-
Les principaux avantages de l'analyse non statistique des données consistent à rendre possible l'examen de nombreuses questions et notions difficiles à quantifier, favorisant une approche plus holistique.
En outre, l'analyse non statistique permet à l'évaluateur de tirer profit de toute l'information disponible. Il se peut que les constatations tirées d'une analyse de ce genre soient plus détaillées que celles tirées d'une analyse purement statistique.
-
Toutefois, les conclusions fondées uniquement sur une analyse non statistique risquent de ne pas être aussi crédibles que d'autres fondées sur de l'information et des données provenant de sources multiples, ainsi que sur plusieurs méthodes d'analyse.
-
La validité et l'exactitude des conclusions d'une analyse non statistique sont fonction de la compétence et du jugement de l'évaluateur; leur crédibilité dépend de la logique des arguments présentés.
Cook et Reichardt (1979), Kidder et Fine (1987) ainsi que Pearsol (1987), entre autres, ont étudié ces questions de façon plus détaillée.
Références : Analyse non statistique de l'information qualitative
Cook, T.D. et C.S. Reichardt, Qualitative and Quantitative Methods Evaluation Research, Thousand Oaks : Sage Publications, 1979.
Guba, E.G., «Naturalistic Evaluation,» in Cordray, D.S., et al., éd., Evaluation Practice in Review, Vol. 34 de New Directions in Program Evaluation, San Francisco : Jossey-Bass, 1987.
Guba, E.G. et Y.S. Lincoln, Effective Evaluation : Improving the Usefulness of Evaluation Results Through Responsive and Naturalistic Approaches, San Francisco : Jossey-Bass, 1981.
Krueger, R.A., Focus Groups : A Practical Guide for Applied Research, Thousand Oaks : Sage Publications, 1988.
Levine, M., «Investigative Reporting as a Research Method : An Analysis of Bernstein and Woodward's All the President's Men», American Psychologist, Vol. 35, 1980, p. 626 à 638.
Miles, M.B. et A.M. Huberman, Qualitative Data Analysis : A Sourcebook of New Methods, Thousand Oaks : Sage Publications, 1984.
Nachmias, C. et D. Nachmias, Research Methods in the Social Sciences, New York : St. Martin's Press, 1981, chapitre 7.
Patton, M.Q., Qualitative Evaluation Methods, Thousand Oaks : Sage Publications, 1980.
Pearsol, J.A., éd., «Justifying Conclusions in Naturalistic Evaluations», Evaluation and Program Planning, Vol. 10, No. 4, 1987, p. 307 à 358.
Rossi, P.H. et H.E. Freeman, Evaluation : A Systematic Approach (2e édition), Thousand Oaks : Sage Publications, 1989.
Van Maasen, J., éd., Qualitative Methodology, Thousand Oaks : Sage Publications, 1983.
Webb, E.J., et al., Nonreactive Measures in the Social Sciences (2e édition), Boston : Houghton Mifflin, 1981.
Williams, D.D., éd., Naturalistic Evaluation, Vol. 30 de New Directions in Program Evaluation, San Francisco : Jossey-Bass, 1987.
5.4 Analyse des autres résultats des programmes
Les évaluations ont généralement pour objet de mesurer les résultats directs des programmes. Or, il arrive fréquemment que les programmes aient des répercussions plus générales ou à plus long terme qui présentent elles aussi de l'intérêt. On analyse fréquemment ces répercussions en transformant les résultats directs mesurés de façon à les déterminer. Au chapitre 1, nous avons distingué trois types de résultats d'un programme, à savoir :
- les extrants (qui sont de nature opérationnelle);
- les retombées intermédiaires (y compris les avantages pour les clients du programme et, parfois, les inconvénients imprévus pour le client et pour d'autres personnes);
- les retombées définitives (qui sont étroitement liées aux objectifs du programme et habituellement aux objectifs globaux du gouvernement, c'est-à -dire les avantages économiques, l'amélioration de la santé, de la sécurité et du mieux-être).
Dans les analyses de ce genre, on utilise normalement un modèle analytique conçu pour transposer les résultats des deux premiers types en résultats du troisième (ou en résultats différents du deuxième) :
| Activités du programme |
» |
Extrants opérationnels/ Avantages pour les clients |
» |
Avantages pour les clients/ retombées |
Prenons un cas bien simple d'application de cette méthode, celui du programme d'enseignement de la lecture aux immigrants qui est censé améliorer leurs perpectives d'emploi. L'enchaînement logique du programme est présenté graphiquement de la façon suivante :
| Programme d'enseignement de la lecture |
» |
Accroissement des compétences en lecture |
» |
Augmentation des revenus/ meilleures perspectives d'emploi |
Dans un cas comme celui-là , on emploierait une stratégie d'évaluation visant à déterminer l'effet incrémentiel du programme d'enseignement de la lecture sur les compétences à cet égard, puis on prendrait des mesures. On utiliserait ensuite un modèle préétabli pour transformer les changements observés des compétences en lecture des participants en résultats escomptés pour leurs revenus et leurs perspectives d'emploi : les améliorations observées en ce qui concerne les compétences en lecture seraient donc transformées en retombées pour les perspectives d'emploi et les revenus, le tout étant fondé sur des recherches antérieures qui ont un établi un lien entre ces variables et les compétences en lecture.
Il faut observer que toutes les analyses de ce genre sont des solutions de rechange à l'évaluation directe des résultats généraux d'un programme. Dans notre exemple, l'évaluateur pourrait mesurer directement les retombées du programme en ce qui concerne la capacité des participants d'obtenir des emplois mieux rémunérés. Il pourrait notamment se servir d'un modèle quasi expérimental pour comparer un groupe de participants au programme avec un groupe témoin afin de déterminer si les premiers ont augmenté leurs revenus d'emploi comparativement aux membres du second. Cela dit, les méthodes plus indirectes peuvent toutefois se révéler préférables pour de nombreuses raisons.
-
L'analyse de résultats généraux rend possible l'estimation des retombées à long terme.
Les effets secondaires ne sont pas souvent immédiats, et les contraintes de l'évaluation ne permettraient pas toujours d'assurer un suivi sur une longue période.
-
L'analyse des résultats généraux permet à l'évaluateur de déterminer des retombées qui sont difficiles à mesurer directement.
Il peut être extrêmement difficile ou complexe d'évaluer directement les résultats généraux, particulièrement dans le cadre d'un projet d'évaluation donné. D'une certaine façon, ces méthodes réduisent les risques qui se posent pendant l'évaluation. En effet, lorsqu'on mesure d'abord les résultats immédiats, on peut avoir confiance qu'au moins certains d'entre eux auront été mesurés d'une manière valide. Par contre, en allant directement aux résultats généraux, qui peuvent se révéler difficiles à mesurer, on risque de se retrouver sans aucune mesure valide.
-
L'analyse des résultats généraux est utile pour l'évaluation de retombées générales déjà étudiées.
En raison des difficultés de mesure que nous venons de décrire, l'évaluateur pourrait être tenté d'utiliser un rapport entre les effets à court terme et les résultats généraux d'un programme qui ont été déterminés grâce à des recherches antérieures (si, bien sûr, on dispose d'une telle recherche). Par exemple, dans le cas du programme d'enseignement de la lecture, il est vraisemblable qu'on ait déjà fait des recherches poussées afin d'explorer le rapport entre les compétences en lecture, les perspectives d'emploi et les revenus. En pareil cas, l'évaluateur pourrait se fonder sur les résultats de ces recherches, en décidant d'axer sa stratégie d'évaluation sur la mesure des améliorations des compétences en lecture résultant du programme; l'augmentation des revenus des participants qui s'ensuivrait vraisemblablement serait alors une conclusion qui a déjà été prouvée par des recherches antérieures.
5.5 Utilisation de modèles
Toutes les évaluations servant à établir que certains résultats découlent des activités d'un programme sont fondées sur un modèle implicite ou explicite. Sans théorie sur la façon dont le programme produit des résultats observés, l'évaluateur travaillerait à l'aveuglette et serait incapable de lui attribuer des résultats de façon crédible. Cela ne signifie toutefois pas que les modèles doivent être complètement structurés dès le début du travail d'évaluation. Généralement, ils sont révisés et améliorés en cours de route, à mesure que l'équipe d'évaluation développe ses connaissances.
Les diverses disciplines des sciences sociales ont tendance à adopter des approches quelque peu différentes face aux modèles, mais il reste quand même de nombreux points communs.
Les modèles que nous allons décrire dans cette section sont les suivants :
- modèles de simulation;
- modèles d'entrées-sorties;
- modèles micro-économiques;
- modèles macro-économiques;
- modèles statistiques.
5.5.1 Modèles de simulation
La simulation peut s'avérer utile pour les évaluateurs. Toute transformation des intrants du programme en extrants peut être exposée sur une feuille de calcul et modélisée par un évaluateur ayant une certaine formation et un peu de pratique.
L'évaluateur a souvent recours à un modèle quantitatif explicite parce que ses données sont incertaines. Lorsqu'il doit traiter des intervalles de variation plutôt que des chiffres, en jonglant avec les probabilités, il peut lui être extrêmement utile de pouvoir simuler les probabilités d'extrants ou de résultats. Dans les années 1990, le progiciel qui a amélioré les capacités de simulation des tableurs électroniques a offert cette capacité à de nombreux évaluateurs qui auraient peut-être eu moins tendance à opter pour des approches quantitatives, dans d'autres conditions.
Un modèle de simulation peut transformer des intrants en résultats. Prenons par exemple un programme des Douanes aux postes frontaliers qui sont aménagés au bord des autoroutes, et disons qu'on a formulé une nouvelle série de questions à poser aux points d'entrée. L'administration du nouveau questionnaire prend en moyenne 11 secondes de plus que celle de l'ancien. On pourrait utiliser un modèle pour évaluer ses conséquences sur le temps d'attente des clients.
Un modèle de simulation comporte essentiellement trois composantes, soit des intrants, un modèle mathématique et des extrants. On utilise surtout deux types de modèles mathématiques, les stochastiques, qui font intervenir des variables aléatoires, et les déterministes, qui ne contiennent pas de variables de ce genre.
À certains égards, les modèles de simulation ressemblent aux autres méthodes statistiques, comme à l'analyse de régression, qui sont d'ailleurs susceptibles d'être utilisées pour les établir. Une fois établi, le modèle de simulation traite les intrants comme des données qu'il doit utiliser plutôt que des éléments sur lesquels il doit se fonder. Le modèle mathématique génère des extrants qui peuvent être comparés aux résultats réels.
Les évaluateurs s'intéressent de plus en plus à un modèle de simulation donné, à savoir le modèle de risque fondé sur une feuille de calcul coûts-avantages. Lorsque les intrants du modèle coûts-avantages sont représentés par des approximations et des probabilités (plutôt que comme des données certaines), le modèle de risque produit des données sur les prochaines valeurs et sur les probabilités du résultat essentiel (habituellement la valeur actualisée nette). Ces données peuvent être très utiles pour un gestionnaire qui tente d'évaluer le degré de risque d'un programme, ou pour un évaluateur appelé à faire une évaluation du seuil de tolérance et du risque (voir la section 5.6, Analyse coûts-avantages et analyse coût-efficacité).
Avantages et inconvénients
Le principal avantage des modèles de simulation est qu'il permet à l'évaluateur d'estimer les effets incrémentiels dans des situations complexes et incertaines. Par contre, leur principal inconvénient est d'exiger une excellente compréhension de la dynamique du programme ainsi qu'une certaine maîtrise de l'établissement de modèles quantitatifs.
Il faudrait également noter que les modèles de simulation peuvent fournir de l'information valable ex ante, soit de l'information sur les répercussions éventuelles d'un mode d'action donné avant sa réalisation. De l'information de ce type peut assurément être fort utile avant d'exclure des solutions de rechange indésirables. Ex post, les répercussions réelles d'un nouveau programme ou des changements apportés à un programme existant sont mieux évaluées par les méthodes empiriques, comme une analyse de régression ou les modèles présentés au chapitre 3.
Références : Modèles de simulation
Buffa, E.S. et J.S. Dyer, Management Science Operations Research : Model Formulation and Solution Methods, New York : John Wiley and Sons, 1977.
Clemen, R.T., Making Hard Decisions. Duxbury Press, 1991, sections 1 Ã 3.
Ragsdale, C.T., Spreadsheet Modelling and Decision Analysis, Cambridge (MA) : Course Technology Inc., 1995.
5.5.2 Modèles d'entrées-sorties
Un modèle d'entrées-sorties est un modèle économique statique conçu pour décrire l'interdépendance mutuelle de différentes parties d'une économie. Dans ce contexte, l'économie est considérée comme un système d'activités interdépendantes, c'est-à -dire agissant directement et indirectement les unes sur les autres. Le modèle d'entrées-sorties est utilisé pour décrire la façon dont un secteur utilise comme intrants des extrants d'autres secteurs, et vice versa. C'est donc une déconstruction systématique de l'économie qui décrit l'échange de biens et de services nécessaires à la fabrication de produits finis (biens et services).
Ce genre de modèle peut être utilisé pour dériver des prévisions multisectorielles qui sont intrinsèquement cohérentes avec les tendances économiques, ainsi que des évaluations quantitatives détaillées des effets secondaires directs et indirects d'un programme quelconque, ou de toute combinaison de programmes. Plus précisément, le modèle d'entrées-sorties peut produire une description détaillée de l'effet d'un programme gouvernemental sur la production et la consommation actuelles de biens et de services.
La structure des entrées de chaque secteur de production est expliquée en fonction de sa technologie. Le modèle précise les «coefficients techniques» correspondant à la quantité de biens et de services, y compris la main-d'oeuvre, dont le secteur a besoin pour produire une unité d'extrant. Il précise aussi un ensemble de «coefficients de capital» correspondant à l'ensemble des bâtiments, du matériel et des stocks nécessaires à la transformation de la combinaison voulue d'intrants en extrants. Les caractéristiques de la consommation définissent la demande d'intrants (le revenu, par exemple) de tous les secteurs de production de l'économie, y compris les ménages. On peut donc analyser ces caractéristiques, de même que la production et la consommation de n'importe quel bien ou service.
Pour démontrer l'utilité d'un modèle d'entrées-sorties, il suffit d'imaginer l'effet de mesures fiscales sélectives (hypothétiques) sur l'emploi dans le secteur des télécommunications. Supposons que ces mesures fiscales assurent un traitement préférentiel au secteur et influent donc directement sur la quantité, la composition et le prix de ses extrants, lesquels influent à leur tour sur sa demande et sur son utilisation de main-d'oeuvre. Le modèle fait appel à des coefficients correspondant à l'état actuel de la technologie de pointe et à des équations permettant de préciser la consommation et la production attendues de chaque secteur.
Au départ, on commence par estimer l'importance des changements résultant de l'application des mesures fiscales sélectives, en se fondant sur les valeurs de la consommation et de la production prévues du matériel de télécommunication. Le modèle d'entrées-sorties peut ensuite utiliser comme intrant l'augmentation de la consommation de ce matériel, en produisant comme extrant l'accroissement estimatif de la main-d'oeuvre du secteur des télécommunications résultant des mesures fiscales.
Avantages et inconvénients
Autrefois, on utilisait plus fréquemment les modèles d'entrées-sorties dans les économies à planification centrale. Ces modèles, ponctuels et statiques, sont essentiellement descriptifs et, par conséquent, ils ne sont pas très efficaces pour inférer des effets probables liés aux politiques pour l'avenir.
Malheureusement, on a fréquemment mal utilisé les modèles de ce genre dans les évaluations. Le pire exemple est celui de l'analyse des dépenses de programme dans un secteur afin d'estimer les «effets» supposés qui en auraient résulté, sans tenir compte de l'atténuation des effets négatifs qui sont causés par les mesures fiscales ou les emprunts contractés pour financer le programme.
En outre, dans une économie en pleine évolution, ces modèles présentent un autre inconvénient majeur, puisqu'ils ne tiennent pas nécessairement compte des changements des coefficients de production attribuables au progrès technologique, ni des changements relatifs des prix des intrants. Par conséquent, lorsque ces changements se produisent, le modèle d'entrées-sorties décrit une composition incorrecte des intrants d'un secteur donné, ce qui entraîne des estimations incorrectes des résultats supplémentaires du programme étudié. À cet égard, soulignons que le modèle d'entrées-sorties de Statistique Canada est inévitablement fondé sur des données datant d'un certain nombre d'années, et que, en tant que macro-modèle, il n'est pas particulièrement bien adapté à la description des effets des petites dépenses typiques de la plupart des programmes.
Références : Modèles d'entrées-sorties
Canada, Statistique Canada, La structure par entrées-sorties de l'économie canadienne 1961-1981, Ottawa, avril 1989, no de cat. 15-201F.
Chenery, H. et P. Clark, Inter-industry Economics, New York : John Wiley and Sons, 1959.
Leontief, W., Input-output Economics, New York : Oxford University Press, 1966.
5.5.3 Modèles micro-économiques
Les modèles micro-économiques décrivent le comportement économique d'unités économiques individuelles (personnes, ménages, entreprises ou autres organisations) fonctionnant dans une structure de marché et dans des circonstances données. Comme la plupart des programmes sont dirigés exactement à ce niveau, ces modèles peuvent être extrêmement utiles pour l'évaluateur. Ils sont fondés sur le système des prix et normalement représentés par des équations correspondant aux fonctions de l'offre et de la demande d'un bien ou d'un service. Ces équations décrivent le rapport entre le prix et l'extrant, et il est souvent possible d'en faire une représentation graphique avec des courbes de l'offre et de la demande.
Le rendement des modèles micro-économiques est limité par un certain nombre d'hypothèses. Par exemple, on suppose toujours que les consommateurs se comportent de façon à maximiser leur degré de satisfaction et ce, d'une façon rationnelle. Les spécialistes se servent des modèles micro-économiques pour modéliser le comportement du marché, les combinaisons optimales des intrants, le comportement des consommateurs en fonction des coûts et les niveaux de production optimaux.
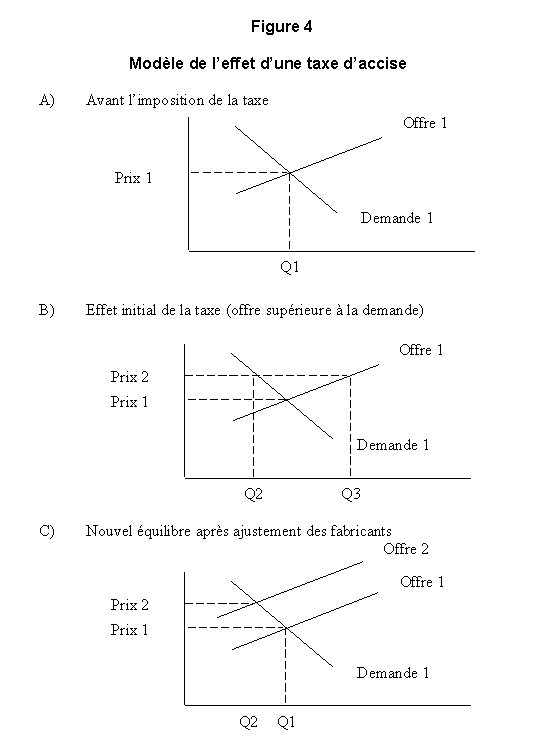
Dans la pratique, on peut avoir recours à des modèles micro-économiques pour estimer les résultats d'un programme dans la mesure où les prix et les extrants peuvent en décrire les effets. La figure 4 est un exemple d'un modèle micro-économique permettant de décrire l'effet qu'un programme de taxe d'accise sur les cigarettes aurait sur le revenu des fabricants ou sur le tabagisme chez les adolescents.
D'après la figure 4, le prix et la quantité de cigarettes produites et consommées avant l'imposition de la taxe d'accise correspondraient respectivement à P0 et Q0. La taxe d'accise ferait augmenter le coût des cigarettes et cette augmentation serait représentée dans le modèle micro-économique par une courbe de l'offre croissante. Le nouveau prix serait donc plus élevé et la nouvelle production plus faible qu'avant l'imposition de la taxe d'accise. À ce moment-là , les recettes de l'industrie des cigarettes équivalaient à P0 x Q0, mais depuis, avec la nouvelle taxe d'accise, elles sont tombées à P1 x Q1. Cette baisse des recettes des fabricants de cigarettes par suite de l'imposition de la taxe d'accise serait fonction de la pente des courbes de l'offre et de la demande qui est elle-même déterminée par plusieurs facteurs.
Avantages et inconvénients
Il faut normalement avoir recours à un économiste pour établir un modèle micro-économique des effets d'un programme, mais cela en vaut souvent la peine, puisque ces modèles peuvent apporter beaucoup d'information sur la raison d'être d'un programme et fournir une base pour mesurer ses effets et son efficacité.
Références : Modèles micro-économiques
Henderson, J. et R. Quandt, Micro-economic Theory, New York : McGraw-Hill, 1961.
Polkinghorn, R.S., Micro-theory and Economic Choices, Richard Irwin Inc., 1979.
Samuelson, P., Foundations of Economic Analysis, Cambridge (MA) : Harvard University Press, 1947.
Watson, D.S., Price Theory in Action, Boston : Houghton Mifflin, 1970.
5.5.4 Modèles macro-économiques
Les modèles macro-économiques sont essentiellement utilisés pour des études sur l'inflation, le chômage et les sujets faisant appel à d'importants ensembles de données, comme le produit national brut. On s'en sert pour tenter d'expliquer et de prédire les rapports entre ces variables.
Ce sont des modèles utiles parce qu'ils révèlent les retombées économiques - une amélioration de la production, du revenu ou de l'emploi ou encore une hausse des taux d'intérêt ou de l'inflation - les plus susceptibles de découler de l'application d'une politique ou de l'exécution d'un programme monétaire et financier.
Voici un exemple d'utilisation d'un modèle macro-économique : supposons qu'un évaluateur cherche à évaluer les retombées sur l'emploi d'un programme gouvernemental de subvention de certains types d'exportation et que les effets du programme sur les ventes à l'exportation ont déjà été mesurés. Les données sur l'accroissement incrémentiel de ces ventes seraient introduites dans un modèle macro-économique de l'économie canadienne qui pourrait alors estimer les retombées du programme sur l'emploi.
Avantages et inconvénients
Le modèle macro-économique a l'avantage de préciser les liens critiques entre les variables générales globales. En outre, il permet de brosser un tableau général qu'on peut ensuite utiliser pour comparer des programmes canadiens à des programmes analogues mis en oeuvre dans d'autres pays (à condition que les hypothèses et les critères de validité du modèle demeurent intacts).
Pour l'évaluation des résultats d'un programme, le modèle macro-économique présente toutefois de graves inconvénients. En effet, il peut aboutir à des résultats erronés si l'on omet des facteurs clés. En outre, ses données des intrants sont habituellement dérivées d'un autre modèle plutôt que directement mesurées, ce qui ajoute un autre élément d'incertitude à l'analyse.
Enfin, dans bien des cas, la valeur prédictive, surtout à court terme, du modèle macro-économique laisse vraiment à désirer. Néanmoins, c'est un outil qu'on peut utiliser avec profit si les retombées dérivées à l'étude sont à long terme et si l'évaluation porte sur un programme important pour l'économie.
Références : Modèles macro-économiques
Gordon, R.A., Economic Instability and Growth : The American Record, Harper & Row, 1974.
Heilbroner, R.L. et L.C. Thurow, Economics Explained, Toronto : Simon and Schuster Inc., 1987.
Nelson, R., Merton, P. et E. Kalachek, Technology, Economic Growth and Public Policy, Washington (DC) : Brookings Institute, 1967.
Okun, A., The Political Economy of Prosperity, Norton, 1970.
Silk, L., The Economists, New York : Avon Books, 1976.
5.5.5 Modèles statistiques
Les études d'évaluation font appel à beaucoup de types de modèles statistiques dont le plus simple est une présentation de données relatives à une seule variable organisée de façon à en illustrer la configuration. Les tableaux de corrélation de deux variables sont l'instrument de base de l'analyse et du rapport d'évaluation. En fait, même les données analysées à l'aide d'autres modèles sont souvent présentées dans des tableaux de corrélation, pour les rendre plus transparentes et plus accessibles aux décideurs que celles des modèles plus complexes.
Habituellement, les programmes cliniques (dans les domaines de la santé et de l'éducation, par exemple) sont basés sur de petits échantillons, de sorte que l'évaluateur doit utiliser des modèles «d'analyse de la variance» pour en préciser les effets. À l'inverse, les programmes destinés à une grande partie de la population (subventions au commerce ou programmes d'emploi, par exemple) génèrent normalement de vastes ensembles de données et on peut donc avoir recours alors à des «modèles linéaires» d'analyse de régression pour en déterminer les effets. La plupart des programmes du gouvernement fédéral sont de ce dernier type, et c'est pourquoi nous allons nous concentrer sur eux dans cette section.
L'analyse de régression peut servir à vérifier une relation hypothétique, à établir des relations entre des variables qui sont susceptibles d'expliquer les résultats d'un programme, à cerner les cas inhabituels (valeurs aberrantes) qui dévient des normes ou à faire des prévisions sur les retombées futures d'un programme. Il s'agit là d'une technique parfois exploratoire (pour concocter des rapports approximatifs), mais on l'emploie plus souvent comme confirmation et mesure finale d'une relation causale entre le programme et ses effets constatés. De fait, il est important que le modèle de régression se fonde sur un raisonnement a piori au sujet de la causalité. Il faudrait éviter de rechercher des données au hasard, au risque d'obtenir des résultats sans valeur, et c'est pourquoi il faut s'efforcer de spécifier et de calibrer le modèle en utilisant seulement la moitié des données disponibles pour ensuite déterminer sa capacité de prédiction des résultats révélés par l'autre moitié des données. S'il est un bon prédicteur, le modèle est probablement robuste.
Il faut se rappeler que la corrélation n'implique pas nécessairement un rapport de causalité. Par exemple, deux variables peuvent être simplement corrélées simplement parce qu'elles sont toutes deux causées par une troisième variable. Ainsi, on peut établir une corrélation entre la température diurne élevée et le nombre de prêts agricoles consentis parce que les deux se produisent surtout en été, mais cela ne veut pas dire que les prêts agricoles sont consentis parce qu'il fait chaud durant la journée.
L'analyse de régression tend aussi à inverser le rapport de causalité; c'est d'ailleurs une de ses difficultés reconnues. On peut observer, par exemple, que les entreprises qui obtiennent des stimulations d'incitation d'un programme d'aide au commerce extérieur augmentent leurs ventes à l'exportation. Or, cela peut s'expliquer simplement du fait que les entreprises qui ont de grosses ventes à l'étranger sont plus crédibles que les autres, et qu'il leur est donc plus facile d'obtenir des subventions. On pourrait aussi dire que ce sont leurs ventes à l'étranger qui font obtenir des subventions aux entreprises, plutôt que l'inverse.
Les modèles statistiques ont souvent une importance cruciale pour la détermination des effets incrémentiels. Par exemple, Santé Canada pourrait utiliser un modèle épidémiologique pour préciser les effets de sa Stratégie nationale sur le sida, tandis que le ministère des Finances Canada pourrait utiliser un modèle des revenus pour estimer les effets fiscaux d'un régime éventuel d'aide à la famille. Pour arriver à constituer de tels modèles, il faut généralement une connaissance approfondie du secteur de programmes analysé, ainsi qu'une maîtrise de la technique statistique utilisée.
Avantages et inconvénients
Les modèles statistiques sont polyvalents. Bien construits, ils fournissent des estimations très utiles des résultats d'un programme. Toutefois, ils doivent être bien spécifiés et validés si l'on veut que les résultats soient fiables, ce qui n'est pas toujours aussi facile qu'on pourrait le croire à prime abord.
En outre, l'évaluateur n'arrive pas toujours à faire des inférences à partir d'un modèle statistique. Il se peut par exemple que le modèle porte uniquement sur certains groupes d'âge, ou seulement sur des personnes de certaines régions, auquel cas il est souvent impossible, à partir des résultats, d'en généraliser les effets éventuels à d'autres groupes d'âge ou à d'autres régions.
Références : Modèles statistiques
Chatterjee, S. et B. Price, Regression Analysis by Example (2e édition), New York : John Wiley and Sons, 1995.
Fox, J., Linear Statistical Models and Related Methods, with Applications to Social Research, New York : John Wiley and Sons, 1984.
Huff, D., How to Lie with Statistics, Penguin, 1973.
Jolliffe, R.F., Common Sense Statistics for Economists and Others, Routledge and Kegan Paul, 1974.
Mueller, J.H., Statistical Reasoning in Sociology, Boston : Houghton Mifflin, 1977.
Sprent, P., Statistics in Action, Penguin, 1977.
5.6 Analyse coûts-avantages et analyse coût-efficacité
Tous les programmes visent à générer des avantages qui l'emportent sur leurs coûts. Après avoir estimé les divers coûts et avantages résultant du programme, l'évaluateur peut comparer les deux pour déterminer si le programme est valable. Les deux méthodes les plus fréquemment utilisées à cette fin sont l'analyse coûts-avantages et l'analyse coût-efficacité. Généralement, on s'en sert pour obtenir des renseignements sur la valeur actualisée nette d'un programme. Dans l'analyse coûts-avantages, les avantages du programme sont exprimés en termes monétaires et comparés à ses coûts, alors que, dans l'analyse coût-efficacité, les résultats du programme, exprimés en unités non monétaires - par exemple le nombre de vies sauvées - sont comparés à ses coûts exprimés en dollars.
À l'étape de la planification, on peut mener des analyses coûts-avantages et coût-efficacité ex ante (avant coup) en se fondant sur des estimations des coûts et des avantages escomptés. La plupart des ouvrages et des publications sur l'analyse coûts-avantages la considèrent comme un instrument d'analyse a piori, et surtout comme un moyen d'examiner les avantages nets d'un projet ou d'un programme proposé nécessitant des investissements ou des immobilisations considérables (voir par exemple Mishan, 1972; Harberger, 1973; Layard, 1972; Sassone et Schaffer, 1978 et Schmid, 1989).
Lorsqu'un programme fonctionne depuis un certain temps, on peut aussi avoir recours à une analyse coûts-avantages ou coût-efficacité ex post (après coup) pour déterminer si les coûts réels du programme sont justifiés par ses avantages réels. Pour une étude plus détaillée de l'utilisation de l'analyse coûts-avantages dans le contexte de l'évaluation, voir Thompson (1980) ou Rossi et Freeman (1989). Il y a aussi un aperçu de cette méthode dans le Guide de l'analyse avantages-coûts (1997), une publication du Conseil du Trésor, ainsi que dans les études de cas connexes.
L'analyse coûts-avantages consiste à comparer les avantages tangibles et intangibles d'un programme à ses coûts directs et indirects. Après avoir cerné et mesuré (ou estimé) les avantages et les coûts, on les transforme pour les exprimer en termes communs, habituellement monétaires, de façon à pouvoir les comparer en calculant la valeur actualisée nette du programme. Quand les coûts et les avantages sont étalés dans le temps, il faut les actualiser pour les ramener à une année commune avec le taux d'actualisation approprié.
Pour faire une analyse de ce genre, il faut d'abord choisir le point de vue à partir duquel les coûts et les avantages du programme seront calculés. On en reconnaît habituellement trois, soit le point de vue de la personne, le point de vue financier du gouvernement fédéral et le point de vue social (pour l'ensemble du Canada). Les coûts et les avantages d'un programme varient généralement selon le point de vue. Le plus courant pour les analyses avantages-coûts dans l'administration fédérale est le point de vue social, qui tient compte de tous les coûts et avantages pour la société. Toutefois, le point de vue de la personne et le point de vue financier du gouvernement peuvent contribuer à faire ressortir des perspectives différentes sur la valeur du programme ou encore à expliquer les raisons de sa réussite ou de son échec. Rossi et Freeman (1989) ont produit une analyse plus approfondie des différences entre les trois points de vue.
On part du point de vue de la personne pour examiner les coûts et les avantages du programme pour le participant (qui pourrait être une personne, une famille, une entreprise ou une organisation sans but lucratif). Les analyses coûts-avantages pour lesquelles on adopte ce point de vue aboutissent souvent à des rapports avantages-coûts élevés, parce que le gouvernement ou la société subventionnent le programme dont le participant bénéficie.
D'un autre côté, lorsque l'analyse est effectuée du point de vue financier du gouvernement fédéral, les coûts et les avantages sont évalués du point de vue de la source du financement. Il s'agit essentiellement d'une analyse financière dans laquelle on examine les coûts financiers et les avantages financiers directs pour l'État. Les flux de trésorerie qu'on étudierait normalement dans ce contexte comprendraient les coûts d'administration du programme, les sorties de fonds directes (les subventions), les taxes et impôts perçus par le gouvernement (notamment l'impôt sur le revenu des sociétés, l'impôt sur le revenu des particuliers, les taxes de vente fédérale et autres droits), la réduction des prestations d'assurance-chômage ou d'assurance-emploi et les changements éventuels des paiements de péréquation et de transfert.
Par contre, pour l'analyse coûts-avantages du point de vue social, on part du point de vue de l'ensemble de la société, de sorte que l'analyse est à la fois plus exhaustive et plus difficile, puisqu'il faut tenir compte des résultats généraux du programme, et que les prix du marché, qui sont un bon indicateur des coûts et des avantages pour la personne ou pour une organisation (l'État) risquent de ne pas refléter fidèlement la valeur réelle de ces deux variables pour la société. Ils peuvent être faussés, par exemple, en raison des subventions ou des taxes et impôts. Même s'ils ressemblent à ceux qui sont utilisés dans les analyses du point de vue du particulier et de celui du gouvernement, les éléments examinés dans l'analyse coûts-avantages du point de vue social sont appréciés et calculés différemment (voir Weisbrod et al., 1980). Par exemple, les coûts d'opportunité pour la société sont différents de ceux qu'assume un participant au programme. En outre, les paiements de transfert sont exclus des coûts dans le contexte d'une analyse coûts-avantages du point de vue social, puisqu'ils doivent aussi être considérés comme des avantages pour la société et que les deux s'annulent par conséquent.
Les analyses coûts-avantages faites du point de vue du gouvernement ou du point de vue social tendent à produire des rapports avantages-coûts inférieurs à ceux des analyses analogues qui sont réalisées du point de vue de la personne parce que l'État ou la société assument généralement la totalité du coût du programme, alors que la personne, elle, peut bénéficier de tous ses avantages, en n'assumant qu'une fraction infime du coût total. Néanmoins, les analyses coûts-avantages des programmes gouvernementaux devraient être faites du point de vue social.
Pour sa part, l'analyse coût-efficacité exige aussi que les coûts et les avantages du programme étudié soient quantifiés, quoique les avantages (ou les effets) ne sont pas alors exprimés en dollars. Il s'agit plutôt de combiner les données sur les effets ou l'efficacité du programme aux données sur ses coûts de façon à pouvoir comparer le coût et l'efficacité du programme. Par exemple, dans une analyse coût-efficacité, on exprimerait les résultats d'un programme d'éducation en parlant de la progression moyenne d'un niveau de lecture (données sur les résultats) par tranche de 1 000 $ (données sur les coûts) investis dans le programme. Les avantages (effets) sont exprimés en termes quantitatifs - mais pas en dollars - dans l'analyse coût-efficacité.
Ce genre d'analyse est fondé sur les mêmes principes que l'analyse coûts-avantages. Les hypothèses utilisées, par exemple pour le calcul des coûts et l'actualisation, sont les mêmes dans les deux cas. Au fond, l'analyse coût-efficacité permet de comparer et de classer des programmes en fonction du coût pour atteindre certains buts. Les données sur l'efficacité peuvent être combinées avec celles sur les coûts pour déterminer l'efficacité maximale correspondant à un coût donné, ou encore le coût le plus bas permettant d'atteindre un degré d'efficacité particulier.
Les données qui sont nécessaires à l'exécution d'analyses coûts-avantages et coût-efficacité peuvent provenir de diverses sources. Bien entendu, les recherches dans les dossiers détaillés des programmes devraient générer beaucoup d'informations sur les coûts, et ces données peuvent souvent être complétées grâce à des sondages auprès des bénéficiaires. D'autre part, les données sur les avantages peuvent être recueillies par n'importe quelle des autres méthodes dont nous avons déjà parlé dans cette publication.
Supposons par exemple qu'on a entrepris une évaluation pour vérifier l'hypothèse qu'un programme de santé mentale rejetant l'hospitalisation en lui préférant la prestation de soins de santé dans la collectivité serait plus efficace que la méthode de traitement prévalant à l'heure actuelle, et supposons aussi qu'on a employé un modèle expérimental pour obtenir une estimation des effets incrémentiels de ce programme innovateur. Dès que les effets incrémentiels seraient connus, l'analyse coûts-avantages pourrait permettre de les évaluer et de les comparer aux coûts.
Avantages et inconvénients
La documentation sur les avantages et les inconvénients de l'analyse coûts-avantages et de l'analyse coût-efficacité abonde (voir par exemple Greer et Greer, 1982, ainsi que Nobel, 1977). Nous nous contenterons ici de faire valoir succinctement un certain nombre de points à cet égard.
-
L'analyse coûts-avantages porte sur la valeur nette d'un programme.
Il ne s'agit pas, en l'occurrence, d'estimer des avantages et des coûts précis d'un programme, mais plutôt de les résumer de façon qu'on puisse juger et comparer des solutions de rechange. Il faut mesurer dans un autre contexte le degré auquel les objectifs ont été atteints, en faisant appel à un autre modèle d'évaluation et à des méthodes différentes de collecte des données. Par la suite, les données sur les résultats du programme peuvent être utilisées comme intrants pour les analyses globales coûts-avantages et coût-efficacité.
-
L'évaluateur doit aborder la question de l'attribution ou des effets incrémentiels avant de réaliser une analyse coûts-avantages.
Par exemple, de 1994 à 1997, le gouvernement fédéral a mis en oeuvre un programme d'infrastructures à frais partagés avec les municipalités et les provinces. Avant de pouvoir analyser les coûts et les avantages de ce programme ou de ses solutions de rechange, il faudrait établir des mesures des effets incrémentiels afin de déterminer jusqu'à quel point le programme a changé ou accéléré les travaux d'infrastructure municipaux. C'est seulement après avoir déterminé les effets incrémentiels qu'on peut raisonnablement passer à l'évaluation et à la comparaison des coûts et des avantages.
-
Les analyses coûts-avantages et coût-efficacité aident souvent l'évaluateur à déterminer tous les coûts et tous les résultats d'un programme.
-
À elles seules, les analyses coûts-avantages et coût-efficacité ne suffisent pas à expliquer des effets et des résultats particuliers.
Ces techniques ne permettent pas de déterminer pourquoi un objectif donné n'a pas été atteint, ni pourquoi un effet particulier s'est produit. Toutefois, comme elles comparent systématiquement les avantages et les coûts, elles sont utiles puisqu'elles fournissent des renseignements valides aux décideurs.
-
Ces analyses comportent de nombreuses difficultés méthodologiques.
Il est souvent difficile d'exprimer en dollars les avantages et les coûts d'un programme. Il peut être très malaisé d'attribuer une valeur monétaire à des résultats dans les domaines de l'éducation, de la santé (quelle valeur attribuer à la vie humaine ou encore à sa qualité), voire de l'équité et de la répartition du revenu. Toutes les évaluations de cet ordre sont et resteront toujours très discutables. En outre, même lorsqu'on réussit à les exprimer en dollars, les coûts et les avantages doivent être actualisés à un point commun dans le temps afin qu'on puisse les comparer. Les auteurs traitant des analyses coûts-avantages sont loin de l'unanimité à ce sujet. Ils continuent à discuter du taux d'actualisation optimal. Dans son Guide de l'analyse avantages-coûts, le Conseil du Trésor recommande à l'évaluateur de faire une analyse de risque (simulation), avec une fourchette de taux se situant autour de 10 p. 100 par année, compte tenu de l'inflation.
-
L'évaluateur devrait toujours faire une analyse de sensibilité des hypothèses sous-jacentes aux analyses coûts-avantages et coût-efficacité, pour vérifier la solidité des résultats obtenus.
Compte tenu des hypothèses qu'il faut poser pour comparer les avantages et les coûts d'un programme, l'évaluateur aurait intérêt à effectuer une analyse de sensibilité afin de déterminer dans quelle mesure ses conclusions sont fonction de chacune de ses hypothèses. En outre, il devrait s'efforcer de vérifier à quel degré ces conclusions varient lorsque les hypothèses changent. Si les résultats de l'analyse dépendent largement de la valeur d'un intrant donné, il peut valoir la peine de supporter le coût d'études supplémentaires pour vérifier cette valeur. Soulignons que, contrairement à certains autres types de méthodes d'évaluation, l'analyse coût-efficacité permet à l'évaluateur d'effectuer une analyse de sensibilité à la fois systématique et rigoureuse.
-
On a parfois recours à l'analyse coût-efficacité lorsqu'il est trop difficile de convertir en termes monétaires les valeurs qu'elle utilise.
L'analyse coût-efficacité permet parfois à l'évaluateur de comparer et de classer les solutions de rechange mais, comme les avantages ne sont pas convertis en dollars, il est impossible de déterminer la valeur nette du programme ou de comparer des programmes différents en se fondant sur les mêmes critères.
Par contre, l'analyse coûts-avantages permet d'utiliser des techniques grâce auxquelles il est possible de comparer et d'évaluer même des coûts et des avantages qui sont difficiles à mesurer en termes monétaires. Malheureusement, elle exige souvent des ajustements délicats des mesures des coûts et des avantages en raison de l'utilisation d'hypothèses incertaines, ce qui risque d'inquiéter les gestionnaires qui craignent souvent, parfois à raison, que ces hypothèses et ces ajustements risquent de favoriser la manipulation des résultats en privilégiant n'importe quel biais éventuel de l'analyste.
De plus, la détermination des coûts et des avantages est souvent d'autant plus difficile que les ministères et organismes publics ne conservent pas à cet égard des dossiers grâce auxquels il serait facile de les comparer. Pour la plupart des programmes, les données sur les coûts que les services intéressés conservent ont trait à de nombreuses activités et sont organisées pour faciliter la tâche des administrateurs, et non celle de l'évaluateur.
Références : Analyse coûts-avantages et analyse coût-efficacité
Angelsen, Arild et Ussif Rashid Sumaila, Hard Methods for Soft Policies : Environmental and Social Cost-benefit Analysis, Bergen, Norvège : Institut Michelsen, 1995.
Australie, ministère des Finances, Handbook of Cost-benefit Analysis, Canberra, 1991.
Banque mondiale, Institut de développement économique, The Economics of Project Analysis : A Practitioner's Guide, Washington (DC), 1991.
Belli, P., Guide to Economic Appraisal of Development Projects, Washington (DC) : Banque mondiale, 1996.
Bentkover, J.D., Covdlo, V.T. et J. Mumpower, Benefits Assessment : The State of the Art., Dordrecht, Pays-Bas : D. Reidel Publishing Co., 1986.
Canada, Bureau du Vérificateur général, «Le choix et l'application des techniques de collecte des éléments probants en vérification d'optimisation des ressources», Analyse coûts-avantages, Ottawa, 1994, annexe B5.
Canada, Secrétariat du Conseil du Trésor, Guide de l'analyse avantages-coûts, Ottawa, 1997 (doit paraître pendant l'été 1997).
Harberger, A.C., Project Evaluation : Collected Papers, Chicago : Markham Publishing Co., 1973.
Miller, J.C. III et B. Yandle, Benefit-cost Analyses of Social Regulation, Washington : American Enterprise Institute, 1979.
Sang, H.K., Project Evaluation, New York : Wilson Press, 1988.
Sassone, P.G. et W.A. Schaffer, Cost-benefit Analysis : A Handbook, New York : Academic Press, 1978.
Schmid, A.A., Benefit-cost Analysis : A Political Economy Approach, Boulder : Westview Press, 1989.
Self, P., Econocrats and the Policy Process : The Politics and Philosophy of Cost-benefit Analysis, Londres : Macmillan, 1975.
Skaburskis, Andrejs et Fredrick C. Collignon, «Cost-effectiveness Analysis of Vocational Rehabilitation Services», Canadian Journal of Program Evaluation, Vol. 6, No 2, octobre-novembre 1991, p. 1 à 24.
Skelton, Ian., «Sensitivity Analysis in Multi-criteria Decision Aids : A Demonstration of Child Care Need Assessment», Canadian Journal of Program Evaluation, Vol. 8, No. 1, avril-mai 1993, p. 103 à 116.
Sugden, R. et A. Williams, The Principles of Practical Cost-benefit Analysis, Oxford : Oxford University Press, 1978.
Thompson, M., Benefit-cost Analysis for Program Evaluation, Thousand Oaks : Sage Publications, 1980.
Van Pelt, M. et R. Timmer, Cost-benefit Analysis for Non-Economists, Institut d'économie des Pays-Bas, 1992.
Watson, Kenneth, «The Social Discount Rate», Canadian Journal of Program Evaluation, Vol. 7, No 1, avril-mai 1992, p. 99 à 118.
Yates, Brian T., Analyzing Costs, Procedures, Processes, and Outcomes in Human Services, Thousand Oaks : Sage Publications, 1996.
5.7 Résumé
Dans ce chapitre, nous avons décrit plusieurs méthodes d'analyse des données qui devraient faire partie intégrante de la stratégie d'évaluation, dans la pratique. Les éléments de cette stratégie devraient d'ailleurs former un tout cohérent dans lequel les questions à évaluer, le modèle, les méthodes de collecte des données et la technique d'analyse des données optimale devraient s'agencer aussi harmonieusement que possible.
Nous avons étudié une vaste gamme de méthodes d'analyse dans ce manuel, en décrivant plusieurs types d'analyses statistiques et non statistiques d'évaluation des résultats d'un programme et de méthodes d'estimation de leurs retombées, notamment grâce à l'utilisation de modèles, ainsi que des méthodes de détermination des coûts. Il sera bien sûr toujours difficile de décider quand et comment utiliser une méthode donnée, puis de le faire habilement et judicieusement.
- Date de modification :